Introduction
Dans ce rapport nous regarderons les différentes possibilités mises à notre disposition via le package "twitteR" notamment afin de récupérer des tweets et illustrer leur contenu où les opinions des utilisateurs. Nous verrons notamment une méthode afin de récupérer les tweets et nettoyer le texte qu'ils contiennent. De plus, nous regarderons différents nuage de mots afin d'illustrer ces tweets. Dans la suite nous souhaitons analyser les tweets de la sphère politique française. Dans ce but, nous regarderons des tweets tournant autour de personnes politiques ou venant directement des comptes de personnalités politique de notre pays.
Faire un nuage de mot
Regardons d'abord le nuage de mot le plus simple. Le nuage de mot est une représentation très graphique des différents mots les plus utilisés dans un corpus. En effet, on se servira d'une fonction qui pourra nous retourner directement tous les mots en rapport avec un thème particulier et pour ensuite visualiser le resultat de cette recherche par un nuage de mots.
Dans toute la suite de ce rapport nous utiliserons ces différentes librairies :
library("twitteR")
library("tm")
library("RColorBrewer") ## Pour des palettes de couleurs personnalisées
library("wordcloud")
library("dplyr") ## Pour opérateur %>%
library("magrittr") ## fonction extract2
library("stringr") ## str_replace_all
library("markdown")
library("FactoMineR")
library("cluster")
library("ggplot2")
Récupération des tweets
Recherchons maintenant n = 5000 tweets, en français, en rapport avec François Hollande. Nous utilisons ici la fonction tryCatch afin de ne faire notre recherche qu'une seule fois étant donné qu'elle est assez coûteuse en temps. En effet, on essaye de charger le fichier R appelé françoistweet et si on obtient une erreur on effectue notre recherche de n tweets et on les sauvegarde dans un fichier françoistweet afin que la prochaine fois qu'on lance le programme le fichier puisse être chargé par R.
tryCatch({
suppressWarnings(load("françois_tweet"))
}, error = function(cond){
françois_tweet = searchTwitteR("François Hollande", n = 5000, lang = "fr")
save(françois_tweet, file = "françois_tweet")
load("françois_tweet")
})
f_tweet = twListToDF(françois_tweet)
Nous avons maintenant un data.frame contenant 5000 tweets se ramenant à François Hollande. Ces messages ont tous leur lot de métadonnées que l'on n'utilisera pas dans ce rapport. Nous devons donc extraire le texte de ces tweets. Il nous suffit de récupérer la colonne correspondante au texte :
francois_text = f_tweet$text
Nettoyage de texte
Le problème maintenant est que nous ne disposons pas encore de texte utilisable pour notre analyse. En effet, regardons les premiers tweets récupérés pour se rendre compte du problème :
head(francois_text, 10)
## [1] "https://t.co/qoJE6Nak3C \nUne ressemblance à François Hollande non? Hollande pigeon ahah pigeon voyageur \xed\xa0\xbd\xed\xb8\x82\xed\xa0\xbd\xed\xb8\x82 #Hollande #France #pigeon #humour"
## [2] "RT @mediapart: Ségolène Royal, qui possède plusieurs atouts pour François Hollande, pourrait bien lui être utile en 2017 https://t.co/i8Y3y…"
## [3] "Mis à part Paf le chien, à qui François Hollande n'a t il pas proposé de poste ministériel? #tweetprécédent"
## [4] "RT @humourdegauchee: Souleymane Sylla demande à François Hollande de faire du jour de son agression un jour férié."
## [5] "Juvisy-sur-Orge : la voleuse se fait passer pour la fille de François Hollande https://t.co/VSQFAv00Wd"
## [6] "#ecologie Notre-Dame-des-Landes : François Hollande en phase avec ses promesses ? https://t.co/2uZsoVa8Hg"
## [7] "#ecologie Notre-Dame-des-Landes : François Hollande en phase avec ses promesses ? https://t.co/D4RQ8XbAvY"
## [8] "Mélenchon appelle à voter, sans condition, François Hollande au 2è tour, comme prévu. https://t.co/dSOKIyKn9T"
## [9] "RT @eurasies1: François Hollande nous fait le clown mais c'est un faux-cul..comme l'est aussi Sarkozy.. https://t.co/VHKgnMZZae"
## [10] "RT @RFImag: Didier Guillaume @partisocialiste \"Le remaniement ministériel pour affirmer la ligne politique de François Hollande \" #MardiPol…"
Le premier problème que nous rencontrons est que nous regardons des tweets en français, par conséquent il existe des termes accentués dans ces messages. Ces termes peuvent poser problème, notamment à la fonction "tolower" qui permet de passer toutes les lettres en minuscules, et nous souhaitons donc les enlever. Pour cela nous utiliserons une méthode "à la dure".
## On remplace les lettres accentuées par leurs équivalentes non accentuées
francois_text = str_replace_all(francois_text, "à", "a")
francois_text = str_replace_all(francois_text, "â", "a")
francois_text = str_replace_all(francois_text, "ç", "c")
francois_text = str_replace_all(francois_text, "é", "e")
francois_text = str_replace_all(francois_text, "è", "e")
francois_text = str_replace_all(francois_text, "ê", "e")
francois_text = str_replace_all(francois_text, "ù", "u")
francois_text = str_replace_all(francois_text, "ï", "i")
francois_text = str_replace_all(francois_text, "û", "u")
francois_text = str_replace_all(francois_text, "ô", "o")
francois_text = str_replace_all(francois_text, "î", "i")
De plus, nous pouvons nous rendre compte que notre texte contient des caractères indésirables tels que des URLs, des smileys ou autres retweet. Tout cela est normal sur twitter mais si nous voulons obtenir une analyse textuelle cohérente nous devons supprimer tous ces caractères indésirables.
francois_text = str_replace_all(francois_text, "(RT|via)((?:\\b\\W*@\\w+)+)", " ") ## On sort les mot liés aux retweets
# On sort les caractères particuliers
francois_text = str_replace_all(francois_text,"\r", " ") ## retour chariot
francois_text = sapply(francois_text,function(x) iconv(x, "latin1", "ASCII", sub="")) ## émoticônes
francois_text = str_replace_all(francois_text, "[[:punct:]]", " ") ## On sort la ponctuation
francois_text = str_replace_all(francois_text, "[[:digit:]]", " ") ## On sort les nombres
francois_text = str_replace_all(francois_text, "@\\w+", " ") ## On sort les parties liées aux personnes nommés dans les tweets
francois_text = str_replace_all(francois_text,"https.*", " ") ## On sort les lien HTML
# On sort les espaces inutiles
francois_text = str_replace_all(francois_text, "[\t]{2,}", " ") ## plus de deux espaces dans le tweet
francois_text = str_trim(francois_text) ## espaces de début de tweet
Nous pouvons maintenant créer notre corpus :
françois_corpus = Corpus(VectorSource(françois_text))
Nous voulons maintenant pouvoir visualiser les éléments de notre corpus afin de pouvoir éventuellement y voir des problèmes à côté desquels nous serions passés. Pour cela nous pouvons utiliser la fonction suivante :
viewDocs = function(corpus, deb = 1, fin = 10){
## Permet de lire de l'élément deb à l'élement fin du corpus
for (i in deb:fin){
message("Elément du corpus numéro :", i)
corpus %>% extract2(i) %>% as.character() %>% writeLines()
}
}
Regardons donc les premiers éléments de notre corpus.
viewDocs(françois_corpus)
## Elément du corpus numéro :1
## exclusif le portable de francois hollande en ce moment remaniement
## Elément du corpus numéro :2
## presidentielle primaire a gauche melenchon devient lallie objectif de francois
## Elément du corpus numéro :3
## presidentielle primaire a gauche melenchon devient lallie objectif de francois
## Elément du corpus numéro :4
## exclusif le portable de francois hollande en ce moment remaniement
## Elément du corpus numéro :5
## francois hollande n a pas efface la dette fiscale de yannick noah le point
## Elément du corpus numéro :6
## exclusif le portable de francois hollande en ce moment remaniement
## Elément du corpus numéro :7
## ce soir le president francois hollande sera l invite du h de tf et de france
## Elément du corpus numéro :8
## jean luc melenchon meilleur allie de francois hollande pour
## Elément du corpus numéro :9
## jean luc melenchon meilleur allie de francois hollande pour a priori la candidature de jean luc mele
## Elément du corpus numéro :10
## la spectaculaire montee en puissance des relations paris new delhi
Création du nuage de mot
Nous pouvons maintenant créer ce que l'on appelle la Term Document Matrix. Cette matrice compte le nombre d'occurences de chaque terme dans chacun des document du corpus. Un document du corpus est un élément distinct que nous avons utilisé en paramètre dans la fonction VectorSource. Ici, nous n'avons utilisé qu'un seul document. Nous verrons plus loin la méthode pour en utiliser plusieurs.
Si on dispose de n termes différents dans notre corpus de m documents on obtiendra donc une matrice n × m de la forme : $$ \begin{pmatrix} mot_1 & k_1^1 & \cdots & k_1^m \\ \vdots & \vdots & \cdots & \vdots\\ mot_n & k_n^1 & \cdots & k_n^m\\ \end{pmatrix} $$ Où kij est le nombre d'occurences du mot i dans le document j.
word = c(stopwords("french"), "francois", "hollande", "francoishollande")
tdm = TermDocumentMatrix(françois_corpus,
control = list(tolower = TRUE, stopwords = word))
tdm = as.matrix(tdm)
Ici nous sommes obligés, avant de faire la TermDocumentMatrix, de sortir les termes les plus courants de la langue française (stopwords en anglais) ainsi que les termes "francois", "hollande" car il est normal de les retrouver (trop) souvent dans des tweets concernant François Hollande. De plus, le terme "francoishollande" correspond à un Hashtag que l'on retrouve également trop souvent.
Nous pouvons maintenant facilement créer une matrice contenant la fréquence d'apparition de chaque mot dans notre corpus :
word_freqs = sort(rowSums(tdm), decreasing=TRUE)
Pour ensuite créer un data.frame avec chaque mot et sa fréquence d'apparition :
dm = data.frame(word=names(word_freqs), freq=word_freqs)
Et finalement créer notre nuage de mots ne contenant que les 100 mots les plus fréquents afin d'obtenir un nuage lisible. Si nous mettions trop de mots, il est possible que R ne l'affiche pas et/ou que cela ne soit pas très compréhensible.
wordcloud(dm$word, dm$freq, max.words = 100,random.order=FALSE, colors=brewer.pal(8, "Dark2"))
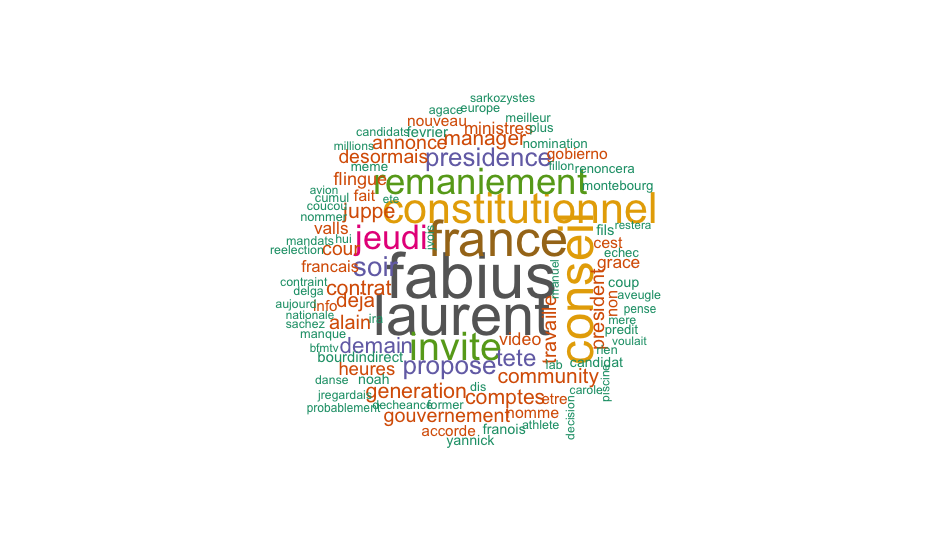
On remarque que les mots les plus utilisés sont notamment "laurent" et "fabius" étant donné que dans l'actualité récente, la polémique a éclaté autour de son refus d'accorder la grâce présidentielle au fils de Laurent Fabius alors qu'il venait de l'accorder à Mme Sauvage qui a tué son mari violent. On peut aussi remarquer l'apparition du mot "grâce" en rapport avec ce sujet.
Faire un nuage de mot comparatif
Dans cette partie nous abordons le sujet du nuage de mot comparatif. Ici
nous ne regardons plus les tweets concernant un sujet particulier, mais
nous comparons les tweets envoyés par plusieurs personnes.
Toujours dans l'idée de regarder la sphère politique française nous
allons voir comment créer notre nuage de mots comparatif en récupérant
les tweets de François Hollande, Manuel Valls, Nicolas Sarkozy et Alain
Juppé.
Récupération des tweets
Nous utiliserons la méthode du tryCatch vue dans le paragraphe précédent et cette fois nous utiliserons la fonction userTimeLine du package twitteR qui permet de récupérer n tweets d'un utilisateur choisi au préalable. Ici nous prendrons, au maximum, n = 500 tweets de chacune des 4 personnalités citées au-dessus.
# François Hollande
tryCatch({
suppressWarnings(load("francois2_tweet"))
}, error = function(cond){
francois2_tweet = userTimeline("fhollande", 500, includeRts = TRUE)
save(francois2_tweet, file = "francois2_tweet")
load("francois2_tweet")
})
f_tweet = twListToDF(francois2_tweet)
# Nicolas Sarkozy
tryCatch({
suppressWarnings(load("nicolas_tweet"))
}, error = function(cond){
nicolas_tweet = userTimeline("NicolasSarkozy", 500, includeRts = TRUE)
save(nicolas_tweet, file = "nicolas_tweet")
load("nicolas_tweet")
})
n_tweet = twListToDF(nicolas_tweet)
# Manuel Valls
tryCatch({
suppressWarnings(load("manuel_tweet"))
}, error = function(cond){
manuel_tweet = userTimeline("manuelvalls", 500, includeRts = TRUE)
save(manuel_tweet, file = "manuel_tweet")
load("manuel_tweet")
})
m_tweet = twListToDF(manuel_tweet)
# Alain Juppé
tryCatch({
suppressWarnings(load("alain_tweet"))
}, error = function(cond){
alain_tweet = userTimeline("alainjuppe", 500, includeRts = TRUE)
save(alain_tweet, file = "alain_tweet")
load("alain_tweet")
})
a_tweet = twListToDF(alain_tweet)
Nous récupérons le texte correspondant à ces tweets :
françois2_text = f_tweet$text
nicolas_text = n_tweet$text
manuel_text = m_tweet$text
alain_text = a_tweet$text
Nettoyage du texte
Ici aussi, nous devons faire du "nettoyage" de texte afin de le faire rentrer dans une TermDocumentMatrix. On utilisera pour cela la fonction suivante dans laquelle on réutilise exactement la même méthode que dans le premier paragraphe.
clean.text = function(x_text, word = stopwords(), lang = "fr")
{
if (lang == "fr"){
x_text = str_replace_all(x_text, "à", "a")
x_text = str_replace_all(x_text, "â", "a")
x_text = str_replace_all(x_text, "ç", "c")
x_text = str_replace_all(x_text, "é", "e")
x_text = str_replace_all(x_text, "è", "e")
x_text = str_replace_all(x_text, "ê", "e")
x_text = str_replace_all(x_text, "ù", "u")
x_text = str_replace_all(x_text, "ï", "i")
x_text = str_replace_all(x_text, "û", "u")
x_text = str_replace_all(x_text, "ô", "o")
x_text = str_replace_all(x_text, "î", "i")
}
x_text = sapply(x_text,function(x) iconv(x, "latin1", "ASCII", sub=""))
x_text = str_replace_all(x_text, "(RT|via)((?:\\b\\W*@\\w+)+)", " ")
x_text = str_replace_all(x_text, "(\r)", " ")
x_text = str_replace_all(x_text, "@\\w+", " ")
x_text = str_replace_all(x_text, "http.+", " ")
x_text = str_replace_all(x_text, "[[:punct:]]", " ")
x_text = str_replace_all(x_text, "[[:digit:]]", " ")
x_text = str_replace_all(x_text, "[ \t]{2,}", " ")
x_text = str_replace_all(x_text, "^\\s+|\\s+$", "")
x_text = str_trim(x_text)
return(x_text)
}
Que l'on applique aux différents textes récupérés dans le but de les rassembler.
f_text = clean.text(françois2_text)
n_text = clean.text(nicolas_text)
m_text = clean.text(manuel_text)
a_text = clean.text(alain_text)
fmna_text = c(paste(f_text, collapse = " "),
paste(n_text, collapse = " "),
paste(m_text, collapse = " "),
paste(a_text, collapse = " "))
Nous pouvons remarquer l'utilisation d'une méthode un peu particulière. En effet, nous sommes obligés de coller les différents textes les uns à la suite des autres avec cette méthode pour que la la fonction tdm considère les textes de chacune des 4 personnes comme étant des éléments distincts. Ici nous enlevons, en plus des stopwords, du nom et du prénom de chacune des personnalités, le terme "nomUtilisateur:". En effet, la fonction userTimeline nous renvoie les tweets de la personne demandée sous la forme : $$ "nomUtilisateur:\ \textit{texte}" $$ Et nous créons désormais notre corpus en assignant bien à chaque document la personne associée.
word = c(stopwords("french"),
"francois", "hollande", "fhollande:",
"nicolas", "sarkozy", "NicolasSarkozy",
"alain", "juppe", "alainjuppe:",
"manuel", "valls", "manuelvalls:")
corpus = Corpus(VectorSource(fmna_text))
tdm = TermDocumentMatrix(corpus, control = list(tolower = TRUE, stopwords = word))
tdm = as.matrix(tdm)
colnames(tdm) = c("Hollande", "Sarkozy", "Valls", "Juppe") ## On assigne les personnes au document correspondant
Création du nuage de mot comparatif
Nous pouvons finalement créer notre nuage de mot comparatif grâce à la fonction comparison.cloud
comparison.cloud(tdm, random.order=FALSE,
colors = c("#00B2FF", "red", "#FF0099", "#6600CC"),
title.size=1.5, max.words=100)

Ici, on voit que le mot le plus utilisé a été utilisé par le compte de François Hollande et correspond au hashtag "votehollande", très probablement pendant sa dernière campagne électorale.
Grâce à la même méthode de traitement du texte, nous pouvons regarder le nuage des mots en communs de ces quatres personnalités politiques. À l'inverse du nuage de mot comparatif ce nuage de mot va mettre en avant les mots qu'ils utilisent le plus et qu'ils ont tous en commun. On utilisera la fonction commonality.cloud du package twitteR comme suit :
commonality.cloud(tdm, random.order=FALSE,
colors = brewer.pal(8, "Dark2"),
title.size=1.5)

Ici, on peut se rendre facilement compte que le seul mot qu'ils aient vraiment en commun est le mot "france".
Comparaison de tweets de deux personnes
Dans cette cette section, nous allons regarder une nouvelle méthode pour créer un nuage de mots comparatif ou "seulement" deux personnes sont comparées. En effet, dans ce cas nous avons une méthode afin d'avoir un affichage différent du précédent. Pour cet exemple, nous comparerons les tweets de Nicolas Sarkozy et Marine Le Pen.
# récupération des tweets
tryCatch({
suppressWarnings(load("nicolas2_tweet"))
}, error = function(cond){
nicolas2_tweet = userTimeline("NicolasSarkozy", 1500, includeRts = TRUE)
save(nicolas2_tweet, file = "nicolas2_tweet")
load("nicolas2_tweet")
})
n_tweet = twListToDF(nicolas2_tweet)
tryCatch({
suppressWarnings(load("marine2_tweet"))
}, error = function(cond){
marine2_tweet = userTimeline("MLP_officiel", 1500, includeRts = TRUE)
save(marine2_tweet, file = "marine2_tweet")
load("marine2_tweet")
})
ma_tweet = twListToDF(marine2_tweet)
# récupération du texte
nicolas2_text = n_tweet$text
marine2_text = ma_tweet$text
# nettoyage
nicolas2_text = clean.text(nicolas2_text)
marine2_text = clean.text(marine2_text)
# rassemblement des deux textes
nico_marine = c(paste(nicolas2_text, collapse = " "),
paste(marine2_text, collapse = " "))
# création du corpus
corpus = Corpus(VectorSource(nico_marine))
word = c(stopwords("french"),
"nicolas", "sarkozy", "sicolassarkozy",
"marine", "pen", "lepen", "mlp_officiel")
tdm = TermDocumentMatrix(corpus, control = list(tolower = TRUE, stopwords = word))
## Exploitation
nico_marine_df = as.data.frame(inspect(tdm)) ## data.frame contenant le nombre d'apparition de chaque mot par personne
names(nico_marine_df) = c("Sarkozy", "Marine") ## on assigne chaque colonne à la bonne personne
nico_marine_df = subset(nico_marine_df, Sarkozy > 2 & Marine > 2) ## On enlève les mots très peu utilisés
## On créer une colonne de différences de fréquence
## Afin de déterminer quel mot est plus utilisé par l'un ou l'autre de ces personnalités
nico_marine_df$freq.dif = nico_marine_df$Sarkozy - nico_marine_df$Marine
plus_nico_df = subset(nico_marine_df, freq.dif > 0) ## Mots plus utilisé par Sarkozy
plus_marine_df = subset(nico_marine_df, freq.dif < 0) ## ------------------- Marine Le Pen
nico_egal_marine = subset(nico_marine_df, freq.dif == 0) ## Même fréquence d'apparition chez l'un et l'autre
Maintenant on va définir une fonction qui va nous calculer l'espacement idéal à avoir lors de notre nuage de mots final.
optimal.spacing <- function(spaces)
{
if(spaces > 1) {
spacing <- 1 / spaces
if(spaces%%2 > 0) {
lim = spacing * floor(spaces/2)
return(seq(-lim, lim, spacing))
}
else {
lim = spacing * (spaces-1)
return(seq(-lim, lim, spacing*2))
}
}
else {
# add some jitter when 0
return(jitter(0, amount=0.2))
}
}
Que l'on applique à nos données en considérant où les espacements seront calculés à partir des différences de fréquences calculées plus tôt.
nico_space = sapply(table(plus_nico_df$freq.dif), function(x) optimal.spacing(x))
marine_space = sapply(table(plus_marine_df$freq.dif), function(x) optimal.spacing(x))
nico_marine_space = sapply(table(nico_egal_marine$freq.dif), function(x) optimal.spacing(x))
Maintenant on peut ajouter une colonne à nos data.frame avec les espacement correspondants à chaque mot.
nico_optim = rep(0, nrow(plus_nico_df))
for(n in names(nico_space)) {
nico_optim[plus_nico_df$freq.dif == as.numeric(n)] <- nico_space[[n]]
}
plus_nico_df = transform(plus_nico_df, Spacing=nico_optim)
marine_optim = rep(0, nrow(plus_marine_df))
for(n in names(marine_space)) {
marine_optim[plus_marine_df$freq.dif == as.numeric(n)] <- marine_space[[n]]
}
plus_marine_df = transform(plus_marine_df, Spacing=marine_optim)
nico_egal_marine$Spacing = as.vector(nico_marine_space)
On peut maintenant afficher notre nuage de mots comparatif alternatif.
ggplot(plus_nico_df, aes(x=freq.dif, y=Spacing)) +
geom_text(aes(size=Sarkozy, label=row.names(plus_nico_df),
colour=freq.dif), alpha=0.7, family='Times') +
geom_text(data=plus_marine_df, aes(x=freq.dif, y=Spacing,
label=row.names(plus_marine_df), size=Marine, color=freq.dif),
alpha=0.7, family='Times') +
geom_text(data=nico_egal_marine, aes(x=freq.dif, y=Spacing,
label=row.names(nico_egal_marine), size=Sarkozy, color=freq.dif),
alpha=0.7, family='Times') +
scale_size(range=c(3,11)) +
scale_colour_gradient(low="red3", high="blue3", guide="none") +
scale_x_continuous(breaks=c(min(plus_marine_df$freq.dif), 0, max(plus_nico_df$freq.dif)),
labels=c("Twitted More by Nicolas Sarkozy","Twitted Equally","Twitted More by Marine Le Pen")) +
scale_y_continuous(breaks=c(0), labels=c("")) +
labs(x="", y="", size="Word Frequency") +
theme_bw() +
labs(title = "Tweets (Sarkozy -vs- Le Pen)") +
theme(plot.title = element_text(family = "Times", size = 18))
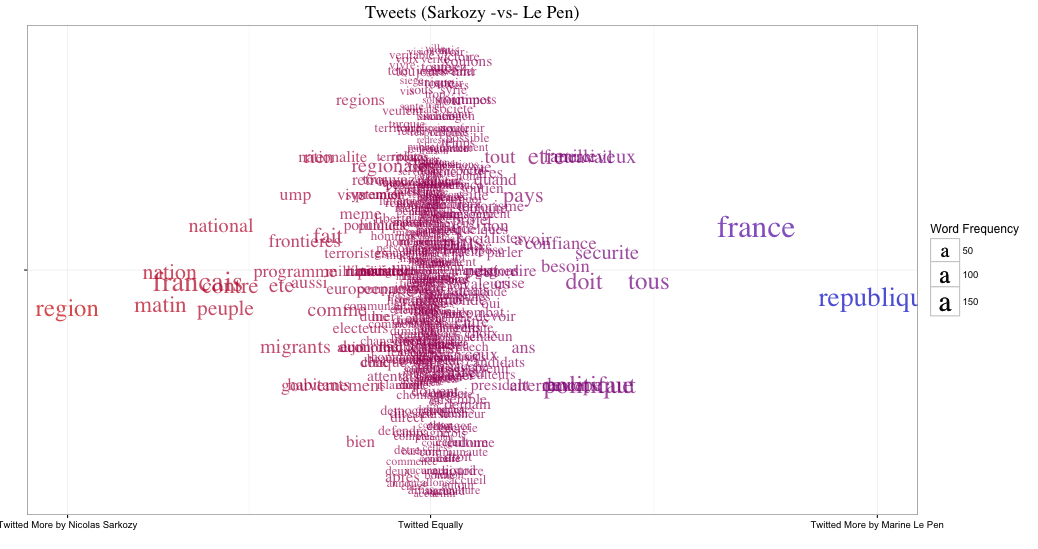
Grâce à ce graphique, on se rend bien compte que, même si un grand nombre de terme utilisé dans les tweets de de ces deux personnes se ressemblent, chacun d'eux a aussi un champ lexical propre. Par exemple, on peut voir que Nicolas Sarkozy parle plus de région et de frontières alors que Marine Le Pen parle plus de république et de sécurité.
Tweets d'un utilisateur
Dans cette partie, on va récupérer les tweets d'un unique utilisateur et analyser ses tweets grâce à une méthode basée sur des méthodes de clustering notamment. Dans cette partie, nous prendrons uniquement les tweets de Marine Le Pen.
tryCatch({
suppressWarnings(load("marine_tweet"))
}, error = function(cond){
marine_tweet = userTimeline("MLP_officiel", 1000, includeRts = TRUE)
save(marine_tweet, file = "marine_tweet")
load("marine_tweet")
})
ma_tweet = twListToDF(marine_tweet)
marine_text = ma_tweet$text
Comme d'habitude, nous nettoyons notre texte, afin de créer notre corpus et obtenir notre TermDocumentMatrix.
marine_text = clean.text(marine_text)
word = c(stopwords("french"), "marine", "pen", "lepen", "MLP_officiel:")
corpus = Corpus(VectorSource(marine_text))
tdm = as.matrix(TermDocumentMatrix(corpus),
control = list(tolower = TRUE, stopwords = word))
Ici, nous regardons une technique qui utilise des méthodes de clustering afin de trouver des groupes de mots, pour faire ressortir les ensembles de mots les plus utilisés. Étant donné que nous avons un échantillon de 1000 tweets et que cela représente énormément de mots, nous ne garderons que ceux utilisés dans 99% des tweets afin que l'on puisse lire quelque chose sur notre graphique final.
w = rowSums(tdm)
tdm1 = tdm[w > quantile(w, probs = 0.99), ]
tdm1 = tdm1[, colSums(tdm1) != 0] # on enlève les colonnes avec uniquement des 0
tdm1_dist = dist(tdm1, method = "binary")
clus1 = hclust(tdm1_dist, method = "ward.D")
plot(clus1, cex = 0.7, main = "", xlab = "", ylab = "")
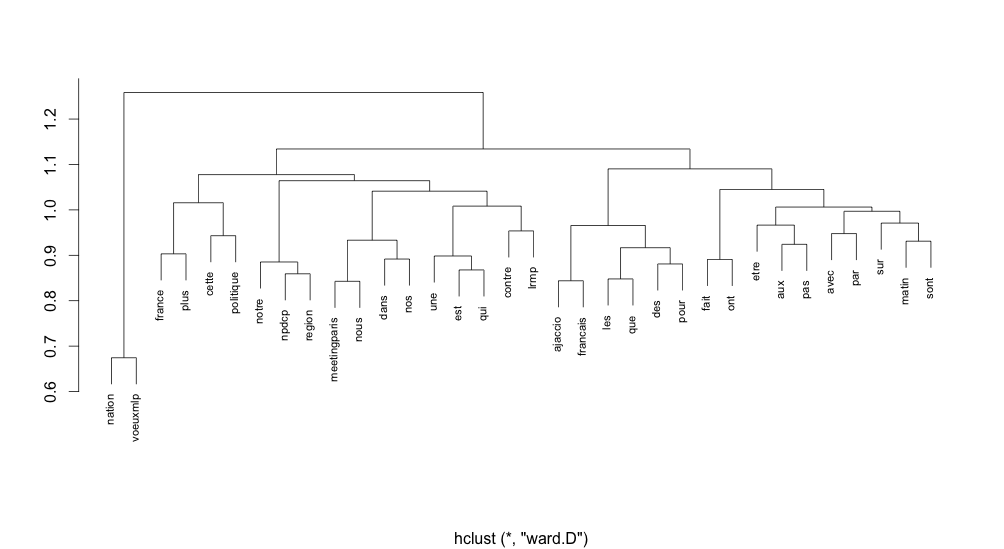
Afin d'obtenir un affichage plus agréable on peut appliquer une "correspondence analysis". Cette méthode est similaire à une ACP mais sur des données catégorielle et non pas continues.
ca = CA(tdm1, graph = FALSE)
plot(ca$row$coord, type="n", xaxt="n", yaxt="n", xlab="", ylab="")
text(ca$row$coord[,1], ca$row$coord[,2], labels=rownames(tdm1),
col=hsv(0,0,0.6,0.5))
title(main="@MLP_officiel Correspondence Analysis of tweet words", cex.main=1)
Pour améliorer encore notre graphique, on fait maintenant une méthode de "partitionning around medoids" qui est une méthode du même type qu'une méthode des k plus proche voisins.
PAM = pam(ca$row$coord[, 1:2], 6)
clus = PAM$clustering
Maintenant on peut améliorer notre graphique.
# Une palette de couleurs
gbrew = brewer.pal(8, "Dark2")
gpal = rgb2hsv(col2rgb(gbrew))
# colors in hsv (hue, saturation, value, transparency)
gcols = rep("", 6)
for (i in 1:6) {
gcols[i] = hsv(gpal[1,i], gpal[2,i], gpal[3,i], alpha=0.65)
}
# affichage avec fréquences
wcex = log10(rowSums(tdm1))
plot(ca$row$coord, type="n", xaxt="n", yaxt="n", xlab="", ylab="")
title("@MLP_officiel Correspondence Analysis of tweet words", cex.main=1)
for (i in 1:6)
{
tmp <- clus == i
text(ca$row$coord[tmp,1], ca$row$coord[tmp,2],
labels=rownames(tdm1)[tmp], cex=wcex[tmp],
col=gcols[i])
}
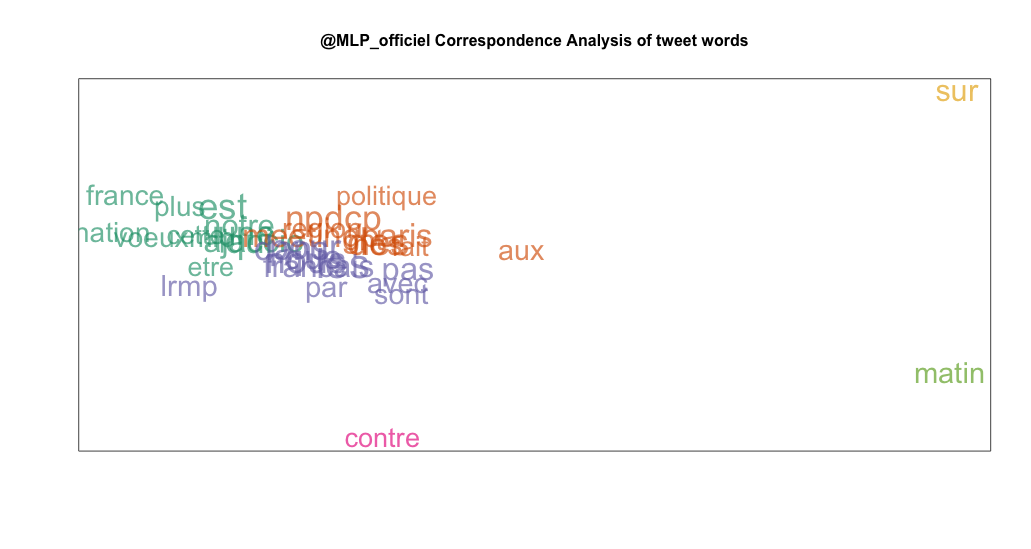
Avec ce graphique on peut se rendre compte que Marine Le Pen utilise très souvent les mêmes mots et très souvent ensemble.