Etude du changement climatique
Sommaire
1. Données
1.1 General Circulation Model (GCM)
1.2 Scénarios
2. Traitement des données
2.1 Création des continents
2.2 Regroupement des
pays
2.3 Extraction des séries d'observations par
continent
3. Etude de variables ayant un impact sur le
changement climatique
3.1 Récupération des données
3.2 Traitement des données
4. Régression
linéaire
5.1 Analyse générale
5. Etude de
cas: Afrique du Sud
5.1 Evolution des anomalies de
températures
5.1 Prédiction des températures
Tout au long de l'histoire de notre Terre, celle-ci a connu des changements climatiques. Ces modifications du climat étaient toujours dus à des causes naturelles. Le changement climatique actuel est, quant à lui, davantage la conséquence des activités de l'homme. Il a également des impacts important au niveau mondial tant pour l'humanité que pour l'environnement. Le climat est la météo moyenne dans une zone donnée observée pendant une période de 30 à 40 ans. Quelques jours de fortes chaleurs durant l'été ou de froid intense pendant l'hiver influent peu sur le climat. Le climat est donc une somme de toutes les sortes de temps sur une période donnée dans une zone donnée. Cependant le climat est déterminé par de nombreux autres facteurs tels que la quantité de précipitation, la présence de montagne et d'océan, etc.
Le climat sur Terre a toujours varié. Au cours de l'histoire de la planète, de grands changements climatiques se sont déjà produits : le climat a constamment changé en raison de causes naturelles et il continuera de changer dans le futur. Ce qui nous amène donc, à explorer une question très actuelle : le réchauffement climatique. L'objectif est d'illustrer cette question par des techniques exploratoires appliquées aux séries d'observation climatologiques du monde. En moyenne, les dernières années apparaissent comme plus chaudes. L'idée est d'essayer de caractériser plus précisément ce qui explique ce réchauffement moyen : consommation de CO2, consommation d'énergie fossile, surface forestières, etc.
1. Données
Le package rWBclimate contient 3 classes de données différentes :
- les modèles GCM
- les ensembles
- les données historiques
Ces trois classes ont deux types de variables différentes:
- les précipitations exprimées en millimètres
- les températures exprimées en degrés Celsius
1.1 General Circulation Model (GCM)
Le modèle GCM est un modèle qui est utilisé pour prédire les changements climatiques. Il est caractérisé de processeur classique simulant des atmosphères terrestre et des océans.
Dans le package, il y a 15 différents modèles GCM:
- bccr_bcm2_0
- csiro_mk3_5
- ingv_echam4
- cccma_cgcm3_1
- cnrm_cm3
- gfdl_cm2_0
- gfdl_cm2_1
- ipsl_cm4
- microc3_2_medres
- miub_echo_g
- mpi_echam5
- mri_cgcm2_3_2a
- inmcm3_0
- ukmo_hadcm3
- ukmo_hadgem1
1.2 Scénarios
Deux scénarios sont déterminés. L'un caractérisant le scénario le plus écologique que l'on appellera "b1", l'autre étant le scénario le plus "pessimiste"" que l'on appellera par la suite "a2". Le scénario a2 et b1 a été chargé par les 15 modèles GCM utilisé dans ce package.
Les données météorologiques prévisionnelles sont accessibles par l'intermédiaire de deux fonctions:
get_model_temp()
get_model_precip()
La première permet de récupérer les moyennes des températures prévisionnelles et la seconde, celle des précipitations.
Les données météorologiques historiques peuvent être récupérées à l'aide des deux fonctions suivantes:
get_historical_precip()
get_historical_temp()
On y récupère pour chaque pays indiqué par son indicatif (ISO 3 lettres), la donnée (température ou précipitation) et le mois/année. De plus, la donnée que l'on récupère est une moyenne calculée sur 12 mois entre 1901 et 2009 pour les pays et entre 1960 et 2009 pour les bassins.
2. Traitement des données
2.1 Création des continents
Avant de commencer toute analyse statistique, il faut regrouper les pays par continent. Pour cela, je récupère la superficie de chaque pays. En effet, pour créer le continent et calculer les moyennes des températures et précipitations, je dois pondérer par leur superficie. En effet, au vu des différentes superficie des pays, les pays n'ont donc pas le même impact sur le continent.Par exemple,la Russie n'a pas autant d'impact que la Belgique sur l'Europe. Cependant j'ai dû enlever des pays car leur série d'observation n'allait pas jusqu'en 2012. Je n'ai gardé que les pays qui ont une série d'observation de 1901 à 2012.
2.2 Regroupement des pays
Je recupère dans un premier temps, un tableau avec les pays, leur ISO (3
lettres) et leur superficie. Ensuite, je crée un tableau de 6 colonnes
avec le nom des continents : - EUR (Europe)
- AFR (Afrique)
- ASI (Asie)
- AMN (Amérique du Nord)
- AMS (Amérique du Sud)
data.sup = read.csv("./DAOUI/continent.csv", sep=";", header=TRUE)
nb_pays_continents<- data.frame(matrix(0,ncol=6,nrow=1))
colnames(nb_pays_continents)<-c("EUR", "AMS", "AMN", "ASI", "OCE", "AFR")
Je crée ensuite les continents et je récupère les données historiques des températures de chaque pays à l'aide de la fonction get_historical_temp() du package rWBclimate. Par exemple pour le continent Europe, je crée un tableau de 112 lignes et une seule colonne contenant seulement des NA puis à l'aide des fonction du package rWBclimate, je remplis mon tableau des données historiques, à savoir les températures et les précipitations.
Je pondère par la superficie à l'aide de la fonction weighted.mean()
for (i in 1:112)
{data.temp.mean$EUR[i] <- weighted.mean(data.temp.EUR[i,],list.EUR$sup)
data.temp.mean$AMS[i] <- weighted.mean(data.temp.AMS[i,],list.AMS$sup)
data.temp.mean$AMN[i] <- weighted.mean(data.temp.AMN[i,],list.AMN$sup)
data.temp.mean$ASI[i] <- weighted.mean(data.temp.ASI[i,],list.ASI$sup)
data.temp.mean$OCE[i] <- weighted.mean(data.temp.OCE[i,],list.OCE$sup)
data.temp.mean$AFR[i] <- weighted.mean(data.temp.AFR[i,],list.AFR$sup)}
2.3 Extraction des séries d'observations par continent
Ces graphiques montrent l'évolution du climat en Europe, Afrique, Amérique du Nord, Amérique du Sud, Asie et Océanie.
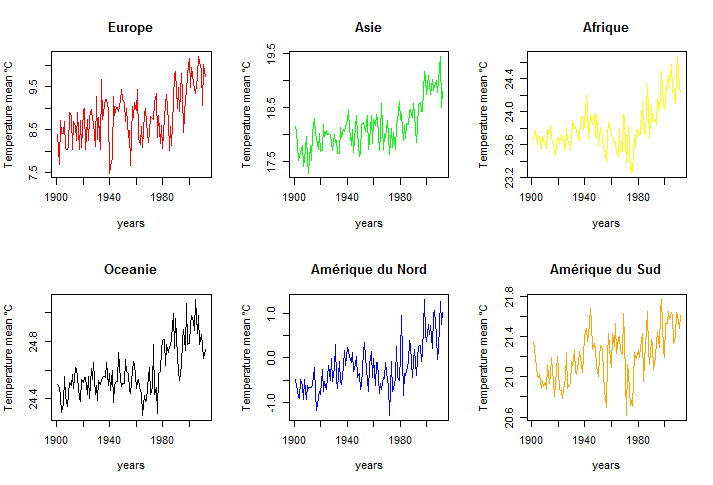
Observations:
Les graphiques ci dessus correspondent aux séries d'observation de
chaque continent entre 1901 et 2012. On remarque une tendance
climatique, en effet on voit une augmentation des températures sur les 6
continents. On remarque qu'en Afrique et en Amérique du Sud en moyenne
les températures sont plutôt élevées comparé aux autres continents.
Je fais la même chose pour les précipitations :
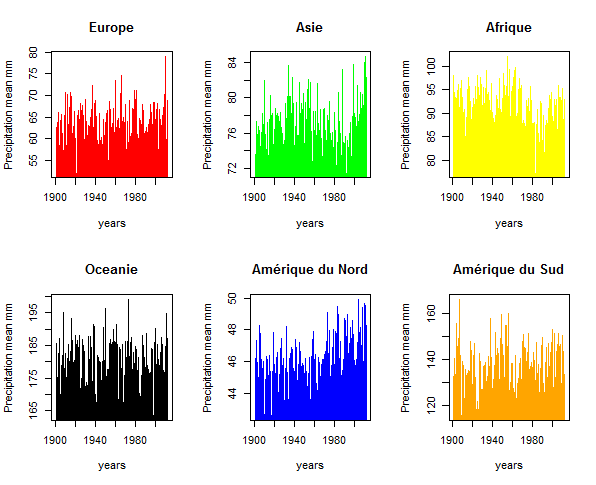
Observations:
Pour la fin de la période, on observe une hausse des précipitations en Europe, en Asie et en Amérique du Nord tandis qu'en Afrique, on observe une baisse. En Amérique du Sud, les données varient mais de façon assez stable et de même en Océanie, on observe la même tendance. Et en Afrique, on a une tendance à la baisse des précipitations.
3. Etude de variables ayant un impact sur le changement climatique
Pour compléter l'étude du changement climatique, j'ai récupéré des données concernant l'utilisation d'énergie par habitant désignant l'énergie primaire avant transformation en des combustibles pour utilisation finale, ce qui équivaut à la production indigène plus les importations et variations du stock moins les exportations et les combustibles pour les bateaux et avions servant au transport international. Aussi, cette base de donnée contient les données par habitant et pour les avoir par pays, il a fallu récupérer une base de donnée avec le nombre d'habitants par pays. De plus, il est intéressant d'étudier les surfaces forestières car les forêts offrent des possibilités d'atténuer en partie, les effets prévus du changement climatique. En effet, lorsque les arbres sont récoltés, brûlés ou meurent, une partie du carbone stockée est de nouveau libérée dans l'atmosphère.
3.1 Données
Avant de les importer, il a fallu les nettoyer et les arranger pour avoir des séries d'observation sur une même durée et toutes débutent en 1971 et finissent en 2012.
data.pop <- read.csv("./DAOUI/population.csv", sep=";",header=TRUE)
data.energy <- read.csv("./DAOUI/Utilisation_Energie_par_habitant.csv", sep=";",header=TRUE)
data.foret <- read.csv("./DAOUI/Foret_en_pourcentage_sup.csv", sep=";",header=TRUE)
Ensuite je trie les données des trois fichiers à savoir l'utilisation d'énergie par habitant, la surface forestière en pourcentage de chaque pays et la population totale par pays. Comme les trois fichiers ne contenaient pas forcément tous les pays, il a fallu éliminer les pays qui n'étaient pas communs aux trois fichiers afin d'éviter toutes erreurs.
data.pop.sup <- merge(data.sup,data.pop,by.x = "ISO",by.y ="Country.Code")
data.pop.sup.energy <- merge(data.pop.sup, data.energy,by.x = "ISO", by.y = "Country.Code")
data.pop.sup.energy.foret <- merge(data.pop.sup.energy, data.foret,by.x = "ISO", by.y = "Country.Code")
Il serait intéressant d'étudier la moyenne des consommation d'énergie fossile par habitant et par pays. En effet, la consommation d'énergie fossile émet beaucoup de CO2 et donc a un impact sur le réchauffement climatique. Il a fallu récupérer la moyenne de cette consommation par continent. Pour cela, j'ai récupéré la population totale de chaque pays afin de calculer une moyenne pondérée de cette consommation pour chaque continent. Cependant, là encore, une dizaine de pays avait des données manquantes, je ne les ai donc pas pris en compte. Cela aura peu d'impact sur l'étude puisque ce sont des pays de très petite superficie, par exemple Monaco ou encore le Vatican que j'ai dû enlevé.
3.2 Traitement des données
Dans un premier temps, je vais réogarniser mes bases de données. Je restreins mon étude entre 1971 et 2012.
La base de donnée contenant la moyenne des consommations d'énergie fossile correspond à une moyenne par habitant. Il faudrait la moyenne des consommations produite par pays et pour obtenir ces résultats je multiplie chaque case de mon tableau de consommation d'énergie fossile par la population totale de chaque pays.
data.energy_pop.reg <- data.pop.reg*data.energy.reg
## The following objects are masked from nb_pays_continents (pos = 3):
##
## AFR, AMN, AMS, ASI, EUR, OCE
Pour obtenir la superficie des forêts afin d'en faire une moyenne pondérée, je vais créer 42 lignes pour pouvoir multiplier les valeurs qui m'intéressent, entre elles.
for (i in 2:time)
{data.sup.reg.EUR[i,]<-data.sup.reg.EUR[1,]
data.sup.reg.AMS[i,]<-data.sup.reg.AMS[1,]
data.sup.reg.AMN[i,]<-data.sup.reg.AMN[1,]
data.sup.reg.ASI[i,]<-data.sup.reg.ASI[1,]
data.sup.reg.OCE[i,]<-data.sup.reg.OCE[1,]
data.sup.reg.AFR[i,]<-data.sup.reg.AFR[1,]}
data.sup.cont <- data.frame(matrix(NA,nrow=time,ncol=6))
colnames(data.sup.cont) <- c("EUR", "AMS", "AMN", "ASI", "OCE", "AFR")
J'ai récupéré la superficie totale en kilomètre carré par continent
for (i in 1:time)
{data.sup.cont[i,] <- c(10180000,18362000,24930000,43810582,8525989,30415873)}
data.energy_pop.mean <- data.frame(matrix(NA,nrow=time,ncol=6))
colnames(data.energy_pop.mean) <- c("EUR", "AMS", "AMN", "ASI", "OCE", "AFR")
data.foret.mean <- data.frame(matrix(NA,nrow=time,ncol=6))
colnames(data.foret.mean) <- c("EUR", "AMS", "AMN", "ASI", "OCE", "AFR")
Je calcule la moyenne des consommations des énergies fossiles pour
chaque continent en pondérant par la population totale de chaque pays.
De même pour le pourcentage de forêt, mais en pondérant cette fois ci
par la superficie. En effet, la base de donnée nous donne le pourcentage
de forêt par pays et pour obtenir le pourcentage de forêt par continent,
il faut donc pondérer par les superficies de chaque pays.
for (i in 1:time)
{data.energy_pop.mean$EUR[i] <- weighted.mean(data.energy.reg.EUR[i,], data.pop.reg.EUR[i,])
data.foret.mean$EUR[i] <- weighted.mean(data.foret.reg.EUR[i,], data.sup.reg.EUR[i,])
data.energy_pop.mean$AMS[i] <- weighted.mean(data.energy.reg.AMS[i,],data.pop.reg.AMS[i,])
data.foret.mean$AMS[i] <- weighted.mean(data.foret.reg.AMS[i,],data.sup.reg.AMS[i,])
data.energy_pop.mean$AMN[i] <- weighted.mean(data.energy.reg.AMN[i,],data.pop.reg.AMN[i,])
data.foret.mean$AMN[i] <- weighted.mean(data.foret.reg.AMN[i,],data.sup.reg.AMN[i,])
data.energy_pop.mean$ASI[i] <- weighted.mean(data.energy.reg.ASI[i,],data.pop.reg.ASI[i,])
data.foret.mean$ASI[i] <- weighted.mean(data.foret.reg.ASI[i,],data.sup.reg.ASI[i,])
data.energy_pop.mean$OCE[i] <- weighted.mean(data.energy.reg.OCE[i,],data.pop.reg.OCE[i,])
data.foret.mean$OCE[i] <- weighted.mean(data.foret.reg.OCE[i,],data.sup.reg.OCE[i,])
data.energy_pop.mean$AFR[i] <- weighted.mean(data.energy.reg.AFR[i,],data.pop.reg.AFR[i,])
data.foret.mean$AFR[i] <- weighted.mean(data.foret.reg.AFR[i,],data.sup.reg.AFR[i,])}
J'importe les données sur les populations totales par continent pour pouvoir multiplier le pourcentage de forêt de chaque continent par la superficie de celui-ci. Elle me sera utile aussi pour obtenir la moyenne des consommations des énergies fossiles par continent.
data.cont.tot <- read.csv("./DAOUI/data_pop_continents.csv", sep=";",header=TRUE)
data.foret.mean.reg <- data.foret.mean*data.sup.cont
data.conso.cont <- data.cont.tot*data.energy_pop.mean
data.conso.cont <- data.conso.cont*(10^-12)
data.temp.reg <- data.frame(matrix(NA,nrow=time,ncol=6))
GES.reg <- data.frame(matrix(NA,nrow=time,ncol=1))
## Warning in `[<-.data.frame`(`*tmp*`, i, , value = structure(list(year =
## 1971L, : 7 variables sont fournies pour remplacer 6 variables
## Warning in `[<-.data.frame`(`*tmp*`, i, , value = structure(list(year =
## 1971L, : 7 variables sont fournies pour remplacer 6 variables
## Warning in `[<-.data.frame`(`*tmp*`, i, , value = structure(list(year =
## 1971L, : 7 variables sont fournies pour remplacer 6 variables
## Warning in `[<-.data.frame`(`*tmp*`, i, , value = structure(list(year =
## 1971L, : 7 variables sont fournies pour remplacer 6 variables
## Warning in `[<-.data.frame`(`*tmp*`, i, , value = structure(list(year =
## 1971L, : 7 variables sont fournies pour remplacer 6 variables
## Warning in `[<-.data.frame`(`*tmp*`, i, , value = structure(list(year =
## 1971L, : 7 variables sont fournies pour remplacer 6 variables
## Warning in `[<-.data.frame`(`*tmp*`, i, , value = structure(list(year =
## 1971L, : 7 variables sont fournies pour remplacer 6 variables
## Warning in `[<-.data.frame`(`*tmp*`, i, , value = structure(list(year =
## 1971L, : 7 variables sont fournies pour remplacer 6 variables
## Warning in `[<-.data.frame`(`*tmp*`, i, , value = structure(list(year =
## 1971L, : 7 variables sont fournies pour remplacer 6 variables
## Warning in `[<-.data.frame`(`*tmp*`, i, , value = structure(list(year =
## 1971L, : 7 variables sont fournies pour remplacer 6 variables
## Warning in `[<-.data.frame`(`*tmp*`, i, , value = structure(list(year =
## 1971L, : 7 variables sont fournies pour remplacer 6 variables
## Warning in `[<-.data.frame`(`*tmp*`, i, , value = structure(list(year =
## 1971L, : 7 variables sont fournies pour remplacer 6 variables
## Warning in `[<-.data.frame`(`*tmp*`, i, , value = structure(list(year =
## 1971L, : 7 variables sont fournies pour remplacer 6 variables
## Warning in `[<-.data.frame`(`*tmp*`, i, , value = structure(list(year =
## 1971L, : 7 variables sont fournies pour remplacer 6 variables
## Warning in `[<-.data.frame`(`*tmp*`, i, , value = structure(list(year =
## 1971L, : 7 variables sont fournies pour remplacer 6 variables
## Warning in `[<-.data.frame`(`*tmp*`, i, , value = structure(list(year =
## 1971L, : 7 variables sont fournies pour remplacer 6 variables
## Warning in `[<-.data.frame`(`*tmp*`, i, , value = structure(list(year =
## 1971L, : 7 variables sont fournies pour remplacer 6 variables
## Warning in `[<-.data.frame`(`*tmp*`, i, , value = structure(list(year =
## 1971L, : 7 variables sont fournies pour remplacer 6 variables
## Warning in `[<-.data.frame`(`*tmp*`, i, , value = structure(list(year =
## 1971L, : 7 variables sont fournies pour remplacer 6 variables
## Warning in `[<-.data.frame`(`*tmp*`, i, , value = structure(list(year =
## 1971L, : 7 variables sont fournies pour remplacer 6 variables
## Warning in `[<-.data.frame`(`*tmp*`, i, , value = structure(list(year =
## 1971L, : 7 variables sont fournies pour remplacer 6 variables
## Warning in `[<-.data.frame`(`*tmp*`, i, , value = structure(list(year =
## 1971L, : 7 variables sont fournies pour remplacer 6 variables
## Warning in `[<-.data.frame`(`*tmp*`, i, , value = structure(list(year =
## 1971L, : 7 variables sont fournies pour remplacer 6 variables
## Warning in `[<-.data.frame`(`*tmp*`, i, , value = structure(list(year =
## 1971L, : 7 variables sont fournies pour remplacer 6 variables
## Warning in `[<-.data.frame`(`*tmp*`, i, , value = structure(list(year =
## 1971L, : 7 variables sont fournies pour remplacer 6 variables
## Warning in `[<-.data.frame`(`*tmp*`, i, , value = structure(list(year =
## 1971L, : 7 variables sont fournies pour remplacer 6 variables
## Warning in `[<-.data.frame`(`*tmp*`, i, , value = structure(list(year =
## 1971L, : 7 variables sont fournies pour remplacer 6 variables
## Warning in `[<-.data.frame`(`*tmp*`, i, , value = structure(list(year =
## 1971L, : 7 variables sont fournies pour remplacer 6 variables
## Warning in `[<-.data.frame`(`*tmp*`, i, , value = structure(list(year =
## 1971L, : 7 variables sont fournies pour remplacer 6 variables
## Warning in `[<-.data.frame`(`*tmp*`, i, , value = structure(list(year =
## 1971L, : 7 variables sont fournies pour remplacer 6 variables
## Warning in `[<-.data.frame`(`*tmp*`, i, , value = structure(list(year =
## 1971L, : 7 variables sont fournies pour remplacer 6 variables
## Warning in `[<-.data.frame`(`*tmp*`, i, , value = structure(list(year =
## 1971L, : 7 variables sont fournies pour remplacer 6 variables
## Warning in `[<-.data.frame`(`*tmp*`, i, , value = structure(list(year =
## 1971L, : 7 variables sont fournies pour remplacer 6 variables
## Warning in `[<-.data.frame`(`*tmp*`, i, , value = structure(list(year =
## 1971L, : 7 variables sont fournies pour remplacer 6 variables
## Warning in `[<-.data.frame`(`*tmp*`, i, , value = structure(list(year =
## 1971L, : 7 variables sont fournies pour remplacer 6 variables
## Warning in `[<-.data.frame`(`*tmp*`, i, , value = structure(list(year =
## 1971L, : 7 variables sont fournies pour remplacer 6 variables
## Warning in `[<-.data.frame`(`*tmp*`, i, , value = structure(list(year =
## 1971L, : 7 variables sont fournies pour remplacer 6 variables
## Warning in `[<-.data.frame`(`*tmp*`, i, , value = structure(list(year =
## 1971L, : 7 variables sont fournies pour remplacer 6 variables
## Warning in `[<-.data.frame`(`*tmp*`, i, , value = structure(list(year =
## 1971L, : 7 variables sont fournies pour remplacer 6 variables
## Warning in `[<-.data.frame`(`*tmp*`, i, , value = structure(list(year =
## 1971L, : 7 variables sont fournies pour remplacer 6 variables
## Warning in `[<-.data.frame`(`*tmp*`, i, , value = structure(list(year =
## 1971L, : 7 variables sont fournies pour remplacer 6 variables
## Warning in `[<-.data.frame`(`*tmp*`, i, , value = structure(list(year =
## 1971L, : 7 variables sont fournies pour remplacer 6 variables
Le graphique ci-dessous montre l'évolution du pourcentage de forêt pour les 6 continents.
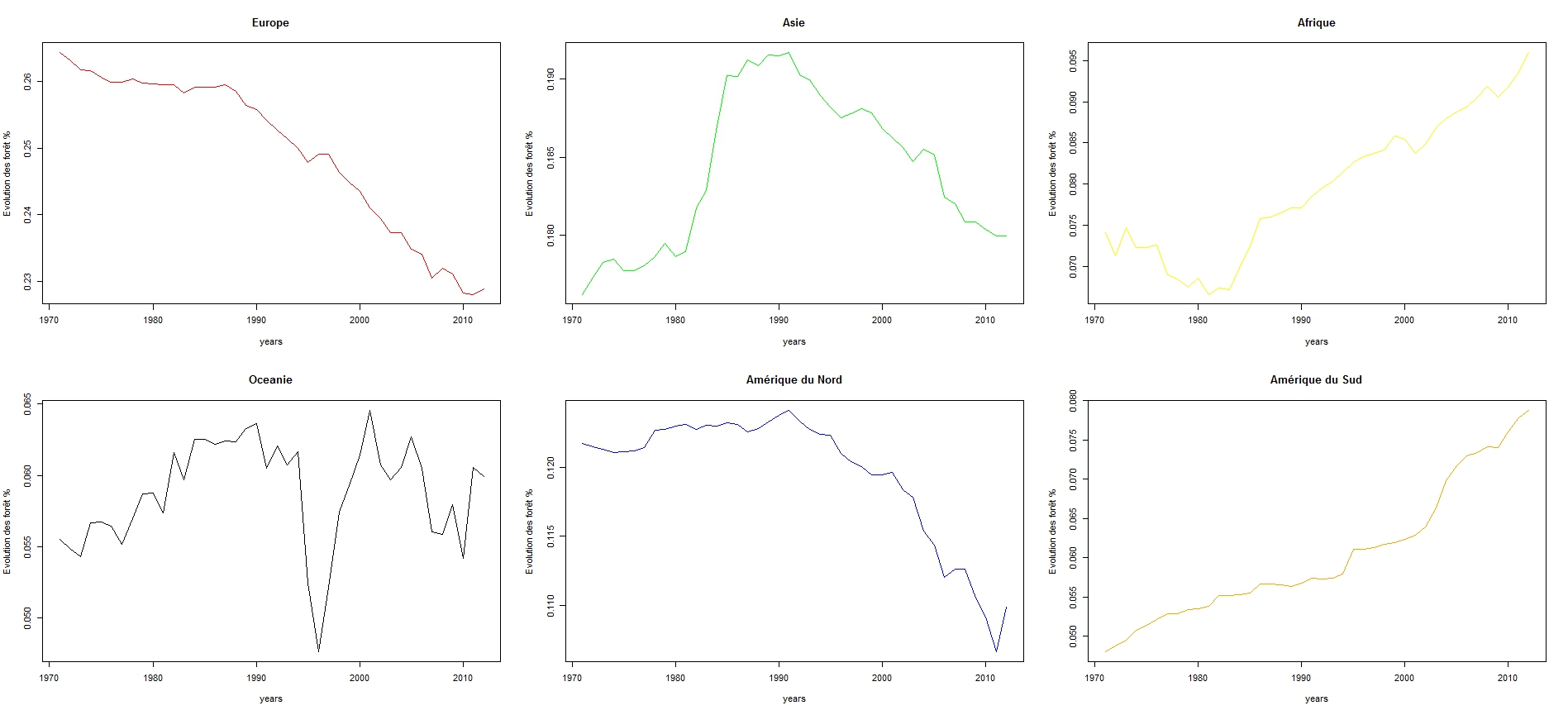
Observations:
En Europe on observe que le pourcentage de forêt diminue fortement. En
effet, on passe de 26% à 23%.
Tandis qu'en Asie, on observe justement une augmentation du taux de
pourcentage de forêt jusqu'en 1990 puis une diminution de ce taux.
En Afrique, on observe certes une augmentation du taux de forêt mais
cela reste faible.
En Océanie, le taux de forêt reste faible. En effet c'est un continent
où il y a beaucoup de désert (cf. Australie). On observe notamment un
pic en 1995 qui pourrait être expliqué par une déforestation. On
constate aussi qu'il y a plus de forêts en Afrique qu'en Amérique du
Sud, ceci peut s'expliquer par les données du Brésil. En effet ces
données amènent à conclure à une augmentation de la surface des forêt
alors qu'en réalité c'est une diminution (cf. Wikipédia).
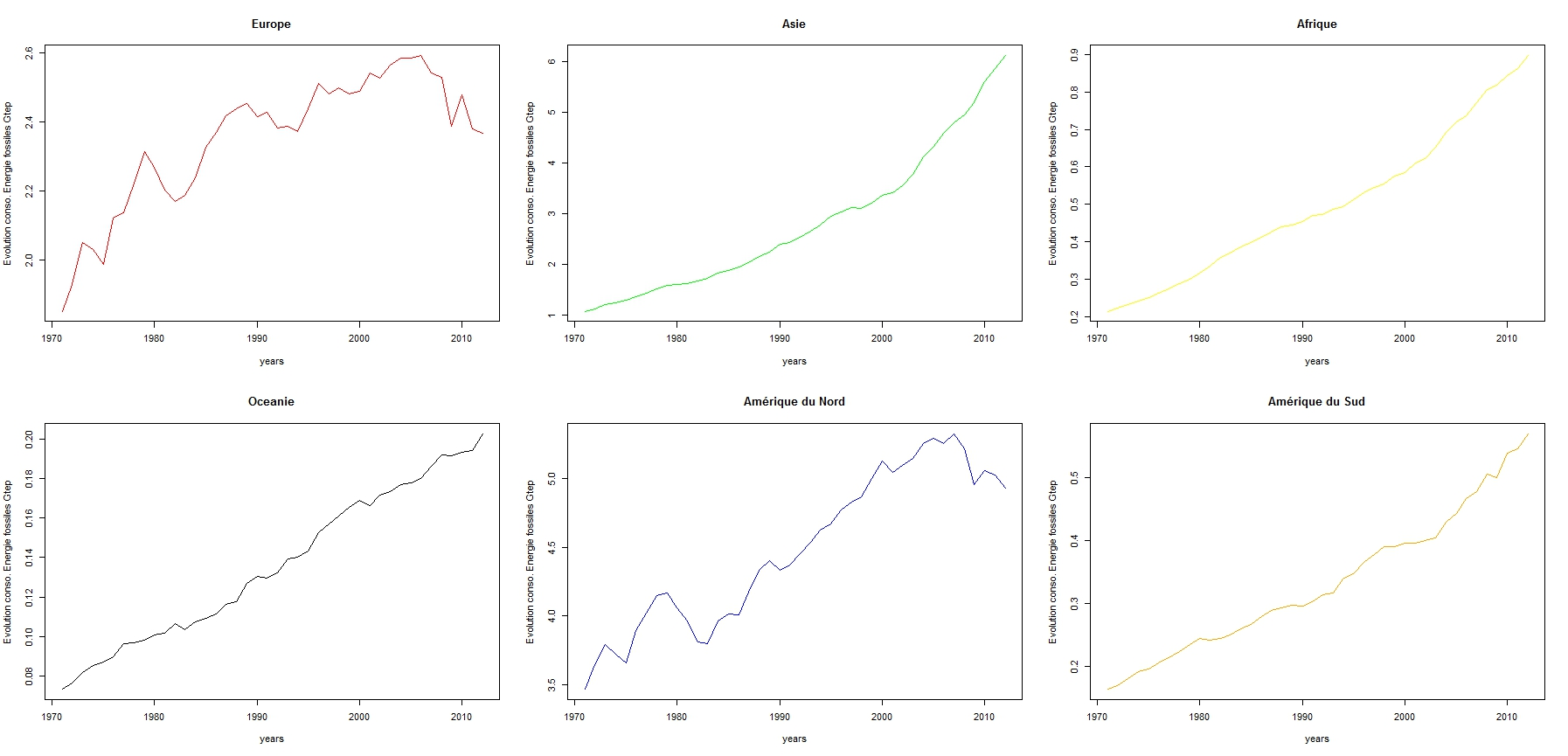
Observations:
Globalement, on constate une augmentation des consommations d'énergie
fossile pour chaque continent. En Europe, cette augmentation est
beaucoup plus flagrante puisque la moyenne des consommations d'énergie
fossile passent de 1 à 6 giga tonne équivalent pétrole entre 1970 et
2003 puis une diminution jusqu'à 5 giga tonne équivalent pétrole.
De même pour l'Océanie, l'augmentation constante entre 1970 et 2012 est
aussi importante puisqu'elle passe de 3.5 à 5.5 giga tonne équivalent
pétrole. Finir les commentaires du graphes.
4. Régression linéaire
summary(reg.OLS.EUR)
##
## Call:
## lm(formula = data.temp.reg$EUR ~ data.foret.mean.reg$EUR + data.conso.cont$EUR)
##
## Residuals:
## Min 1Q Median 3Q Max
## -1.0540 -0.3800 -0.0191 0.3695 1.0457
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 8.994e+00 3.647e+00 2.466 0.0182 *
## data.foret.mean.reg$EUR -4.287e-06 9.795e-07 -4.376 8.76e-05 ***
## data.conso.cont$EUR -1.119e-01 6.113e-01 -0.183 0.8557
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 0.5292 on 39 degrees of freedom
## Multiple R-squared: 0.4784, Adjusted R-squared: 0.4517
## F-statistic: 17.89 on 2 and 39 DF, p-value: 3.074e-06
Observations:
La surface forestière a un impact négatif sur la température car les arbres retiennent du CO2 et donc quand ils meurent ou quand ils sont abbatus, ce CO2 est libéré dans l'atmosphère. Cela implique un réchauffement climatique.
summary(reg.OLS.AMS)
##
## Call:
## lm(formula = data.temp.reg$AMS ~ data.foret.mean.reg$AMS + data.conso.cont$AMS)
##
## Residuals:
## Min 1Q Median 3Q Max
## -0.33424 -0.16403 0.02285 0.11448 0.35034
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 2.166e+01 6.390e-01 33.903 <2e-16 ***
## data.foret.mean.reg$AMS -7.511e-07 9.769e-07 -0.769 0.4466
## data.conso.cont$AMS 3.070e+00 1.375e+00 2.233 0.0314 *
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 0.1804 on 39 degrees of freedom
## Multiple R-squared: 0.6248, Adjusted R-squared: 0.6055
## F-statistic: 32.47 on 2 and 39 DF, p-value: 4.993e-09
Observations:
L'impact de la surface forestière impacte négativement sur la température mais n'est pas significatif sur la régression. Et la consommation des énergies fossiles impacte positivement et significativement sur la température.
summary(reg.OLS.AMN)
##
## Call:
## lm(formula = data.temp.reg$AMN ~ data.foret.mean.reg$AMN + data.conso.cont$AMN)
##
## Residuals:
## Min 1Q Median 3Q Max
## -0.8812 -0.3242 0.0031 0.2395 1.2990
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) -1.288e+00 3.016e+00 -0.427 0.671728
## data.foret.mean.reg$AMN -5.827e-07 8.188e-07 -0.712 0.480925
## data.conso.cont$AMN 7.142e-01 1.706e-01 4.187 0.000156 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 0.4467 on 39 degrees of freedom
## Multiple R-squared: 0.5147, Adjusted R-squared: 0.4898
## F-statistic: 20.68 on 2 and 39 DF, p-value: 7.53e-07
Observations:
Même analyse que l'Amérique du Nord.
summary(reg.OLS.ASI)
##
## Call:
## lm(formula = data.temp.reg$ASI ~ GES.reg[, 1] + data.foret.mean.reg$ASI +
## data.conso.cont$ASI)
##
## Residuals:
## Min 1Q Median 3Q Max
## -0.44685 -0.16098 0.02369 0.15900 0.33634
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) -5.891e+00 3.084e+00 -1.910 0.0636 .
## GES.reg[, 1] 8.703e-02 1.472e-02 5.913 7.50e-07 ***
## data.foret.mean.reg$ASI -9.898e-07 2.826e-07 -3.502 0.0012 **
## data.conso.cont$ASI -9.762e-01 2.035e-01 -4.798 2.49e-05 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 0.2212 on 38 degrees of freedom
## Multiple R-squared: 0.7643, Adjusted R-squared: 0.7457
## F-statistic: 41.07 on 3 and 38 DF, p-value: 5.251e-12
Observations:
Le gaz à effet de serre impacte positivement la température alors que la surface forestière a un impact négatif. La consommation des énergies fossiles a un impact aussi mais ce n'est pas logique dans le sens où ça devrait impacter positivement. Le coefficient de détermination est à 0.75, donc la variable dépendante qui est la température est epxliqué à 77% par le modèle.
summary(reg.OLS.OCE)
##
## Call:
## lm(formula = data.temp.reg$OCE ~ data.foret.mean.reg$OCE + data.conso.cont$OCE)
##
## Residuals:
## Min 1Q Median 3Q Max
## -0.66987 -0.18723 0.00943 0.23360 0.57790
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 2.060e+01 8.165e-01 25.225 <2e-16 ***
## data.foret.mean.reg$OCE 1.176e-06 1.618e-06 0.727 0.472
## data.conso.cont$OCE 2.097e+00 1.294e+00 1.620 0.113
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 0.3194 on 39 degrees of freedom
## Multiple R-squared: 0.07987, Adjusted R-squared: 0.03268
## F-statistic: 1.693 on 2 and 39 DF, p-value: 0.1973
Observations:
Pas d'impact significatifs. Seuls deux pays étaient présents sur le continent donc l'Australie qui représente la plus grande surface,ce qui pourrait expliquer la faible valeur du coefficient de détermination.
summary(reg.OLS.AFR)
##
## Call:
## lm(formula = data.temp.reg$AFR ~ GES.reg[, 1] + data.foret.mean.reg$AFR +
## data.conso.cont$AFR)
##
## Residuals:
## Min 1Q Median 3Q Max
## -0.30795 -0.13458 -0.01885 0.12464 0.45437
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 1.176e+01 4.806e+00 2.447 0.0191 *
## GES.reg[, 1] 4.103e-02 1.611e-02 2.547 0.0150 *
## data.foret.mean.reg$AFR -6.697e-07 3.418e-07 -1.959 0.0574 .
## data.conso.cont$AFR -1.579e+00 1.583e+00 -0.997 0.3250
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 0.1915 on 38 degrees of freedom
## Multiple R-squared: 0.7904, Adjusted R-squared: 0.7738
## F-statistic: 47.76 on 3 and 38 DF, p-value: 5.739e-13
Observations:
Le gaz à effet de serre a un impact positif sur la température. A l'inverse, la surface forestière a un impact négatif sur la température. Etonnamment, la consommation d'énergie fossile a un impact négatif ce qui n'est pas logique mais comme elle n'est pas significative, je ne la prend pas en compte.
4.1 Analyse Générale:
Cette étude m'a permis de voir les variables qui impactaient sur le changement climatique. En effet, le changement climatique actuel est principalement lié à l'émission des gaz à effet de serre provenant de activités humaines. Ces émissions sont dûes pour plus de 3/4 au dioxyde de carbone (CO2). La consommation des énergies fossiles (production d'énergie, carburant des véhicules, chauffage de l'habitat, industrie) est, de loin, le secteur le plus incriminé. De plus, l'étude sur la surface forestière a aussi un impact sur le changement climatique. Comme expliqué plus haut dans le rapport, la déforestation (arbre tué ou arbre mort) libèrent du dioxyde de carbone dans l'atmosphère qui va donc impliquer une hausse des températures.
5. Etude de cas: Afrique du Sud
5.1 Evolution des anomalies des températures
Je vais m'intéresser de plus près à l'Afrique du Sud. Dans un premier temps, je vais tracer le graphique des anomalies de température.
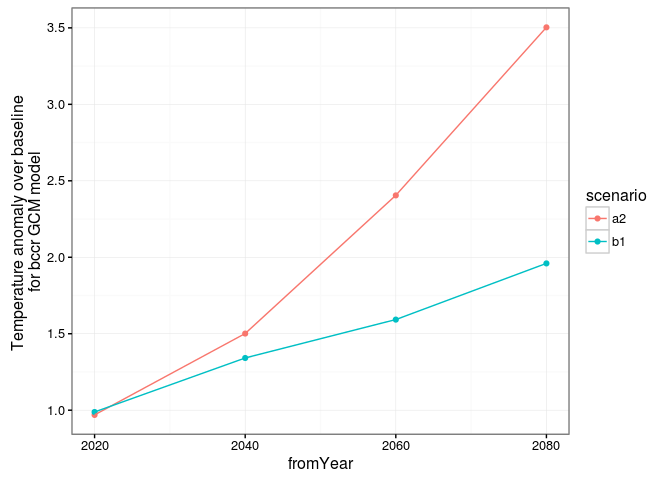
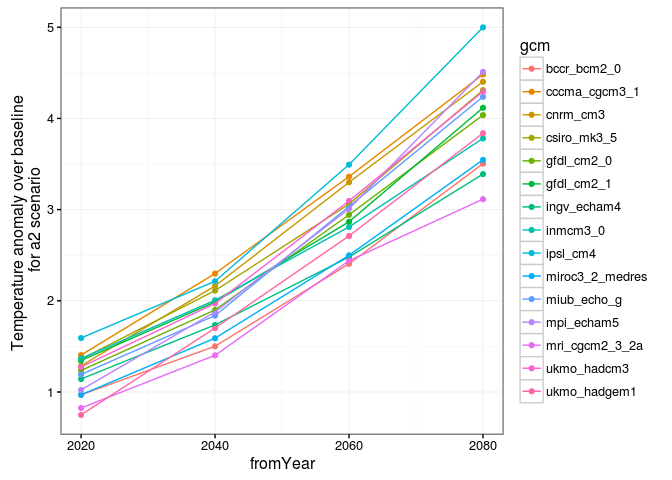
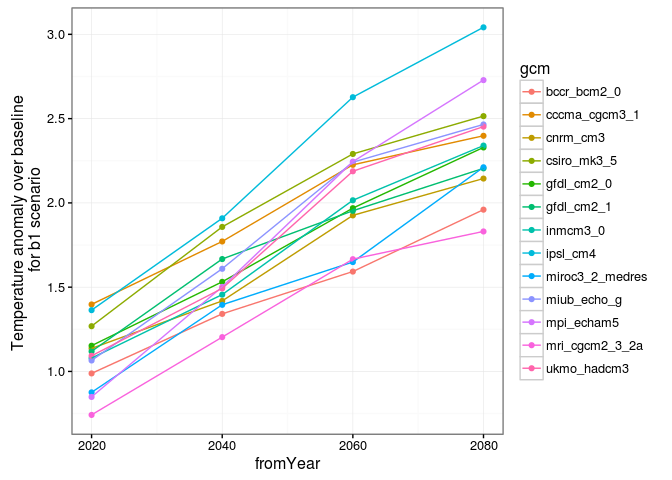
#####Observations: Pour le premier graphique, avec le scénario b1,
on observe des anomalies moins importantes qu'avec le scénario a2.
Pour le deuxième graphique, on remarque un écart significatif entre les modèles mais les courbes sont assez similaires. De plus, on a une augmentation des températures dans tous les cas plus ou moins marquée selon les modèles.
Pour le troisième graphique, on observe à la fin de la période que la pente des courbes se réduit pour certains modèles.
On remarque bien que les anomalies sont plus faibles sur le scénario b1 que sur le scénario a2.
5.2 Prédiction des températures
J'ai tracé des graphiques sur les températures moyennes par mois entre 2020 et 2040.
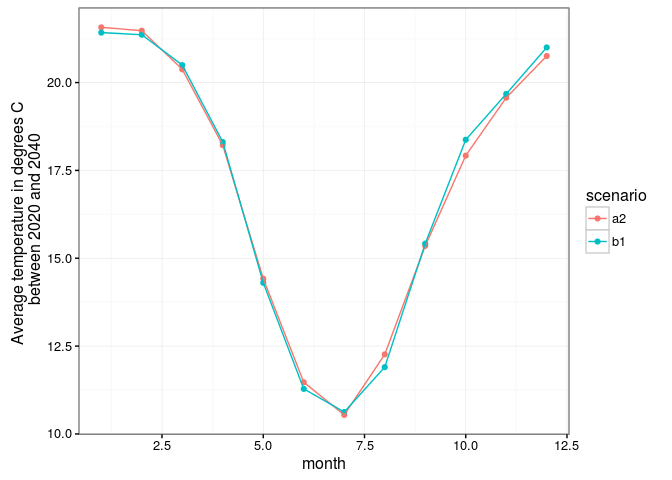
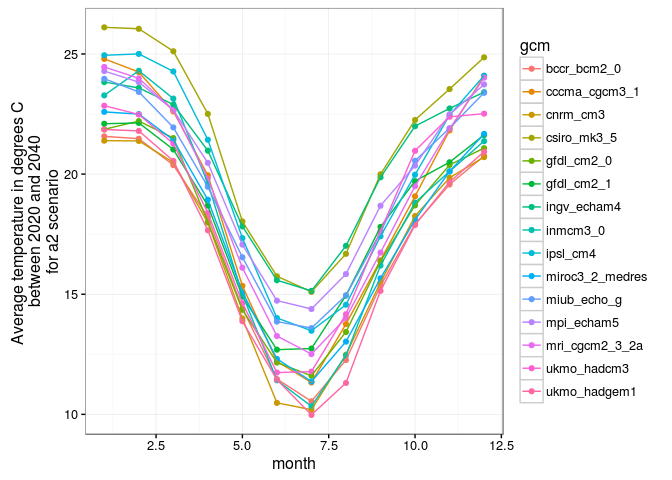
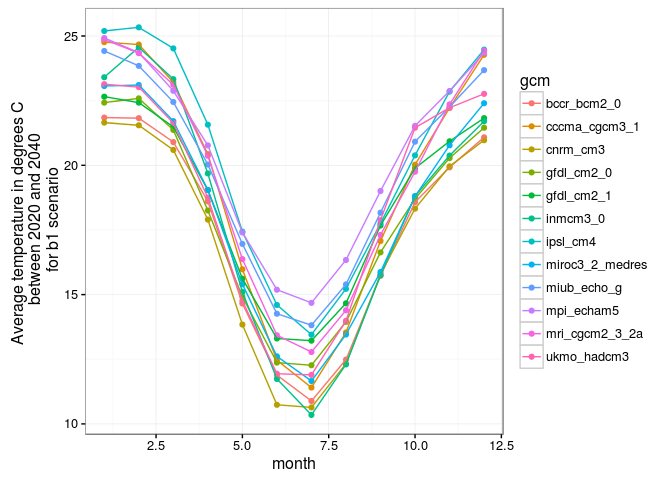
#####Observations:
Le premier graphique représente les températures par mois, on a pas de
différence significative entre les deux scénarios.
Sur le deuxième graphique, on remarque des différentes de températures moyennes par mois sur le scénario a2. Tous les modèles suivent la meme forme de courbe avec des écarts de températures selon les modèles.
Sur le troisième graphique, c'est le même graphique que le 2ème mais avec un scénario moins pessimistes mais on a des températures plus faibles avec les mêmes formes de courbes et des écarts assez significatifs sur les températures selon les modèles.
On remarque bien que le scénario b1 est le plus écologique avec des températures moyennes par mois plus faible que le scénario a2.