Etude autour de l'abstention aux élections municipales de 2008 en France
Le but de ce projet informatique est de s'intéresser au taux
d'abstention aux élections municipales 2008 en France par un traitement
de données libres qui utilise des méthodes de statistiques descriptives
et inférentielles. Nous rechercherons la représentation la plus parlante
du taux d'abstention.
Nous comparerons le taux d'abstention à
d'autres variables.
Est-ce-que le taux d'abstention peut être
expliqué par d'autres indicateurs socio-économiques ?
Est-ce-que
nos analyses permettent de dégager des tendances au niveau national ?
Sommaire
1- Récupération et nettoyage des données
a)
Récupération des données
b) Importation des
fichiers
c) Séparation des données
entre le tour 1 et le tour 2
d)
Modification des codes communes et départements
e) Correspondance avec le code INSEE pour chaque commune
2- Représentation graphique du taux d'abstention en France pour
les élections municipales
3-
Représentation graphique du taux d'abstention en France pour les
élections cantonales 2008
a)
Représentation graphique, découpage par commune
b)
Etude des corrélations entre les taux d'abstention des élections
cantonales et municipales pour le premier tour
4-
Taux d'abstention comparé à des indicateurs économiques et
sociaux
a) Pourcentage des résidences
principales
b) Pourcentage de logements
vacants
c) Taux de chômage
d) Pourcentage de personnes payant l'ISF
e) Etude
des corrélations
f) Régressions linéaires
1- Récupération et nettoyage des données
a) Récupération des données
Nous avons récupéré les données des élections municipales de 2008. Nous avons trois fichiers:
- Les communes de plus de 3500 habitants
- Les communes de moins de 3500 habitants (départements 01 à 48 et outre mer)
- Les communes de moins de 3500 habitants (départements 49 à 95)
b) Importation des fichiers
Les fichiers récupérés sont sous la forme excel donc nous les avons
convertis en .csv pour pouvoir les importer plus facilement sur R.
De plus, comme le fichier comporte deux feuilles, nous avons donc deux
jeux de données: data1 qui comporte les informations sur l'abstention
aux élections municipales 2008 au premier tour et data2 qui comporte les
informations sur l'abstention aux élections municipales 2008 au deuxième
tour.
# Données de plus de 3500 habitants
data1 <- read.table("donnees_data_gouv1.csv", sep=" ", header=TRUE)
data2 <- read.table("donnees_data_gouv2.csv", sep=" ", header=TRUE)
Nous avons fait de même sur les communes de moins de 3500 habitants. Ici data_01_15 contient les informations pour les départements d'outre mers et pour les départements allant de 1 à 15. Les tables dont la forme est data_a_b contiennent les informations pour les départements allant de a à b.
# Données de moins de 3500 habitants
data_01_15 <- read.csv("donnees_communes_01-15.csv", sep=";", header=TRUE)
data_16_26 <- read.csv("donnees_communes_16-26.csv", sep=";", header=TRUE)
data_27_34 <- read.csv("donnees_communes_27-34.csv", sep=";", header=TRUE)
data_35_48 <- read.csv("donnees_communes_35-48.csv", sep=";", header=TRUE)
data_49_59 <- read.csv("donnees_communes_49-59.csv", sep=";", header=TRUE)
data_60_69 <- read.csv("donnees_communes_60-69.csv", sep=";", header=TRUE)
data_70_79 <- read.csv("donnees_communes_70-79.csv", sep=";", header=TRUE)
data_80_88 <- read.csv("donnees_communes_80-88.csv", sep=";", header=TRUE)
data_89_95 <- read.csv("donnees_communes_89-95.csv", sep=";", header=TRUE)
c) Séparation des données entre le tour 1 et le tour 2
On met dans un même tableau toutes les communes de moins de 3500 habitants.
data3 <- rbind(data_01_15,data_16_26,data_27_34,data_35_48,data_49_59,data_60_69,data_70_79,data_80_88,data_89_95)
Puis, nous séparons les données entre le tour 1 et le tour 2 et nous sélectionnons les colonnes code département, code commune, nombre d'inscrits et le nombre d'abstentionnistes pour chaque tour.
# On prend les colonnes code département, code commune, nombre d'inscrits et le nombre d'abstentionnistes au premier tour
data1_1 <- data1[,c(1,3,5,6)]
data4_1 <- data4[,c(1,3,6,7)]
# On prend les colonnes code département, code commune, nombre d'inscrits et le nombre d'abstentionnistes au deuxième tour
data2_2 <- data2[,c(1,3,5,6)]
data5_2 <- data5[,c(1,3,6,7)]
Nous réunissons les deux tables correspondant à chaque tour puis nous enlevons les doublons.
# On réunit les 2 tableaux correspondant au tour 1
data_1tour <- rbind(data1_1, data4_1)
# On réunit les 2 tableaux correspondant au tour 2
data_2tour <- rbind(data2_2, data5_2)
Pour voir le code de cette partie, Cliquer ici
d) Modifications des codes communes et départements
- Arrondissements des grandes villes
Maintenant, dans les deux tableaux que nous avons obtenus, nous modifions les codes communes qui contiennent des caractères puisque ceux-ci correspondent aux arrondissements des grandes villes. Nous devons passer par cette étape pour pouvoir avoir ensuite une correspondance entre les codes communes de cette table et les codes communes dans une autre table que nous allons télécharger contenant le code INSEE pour chaque commune.
- DOM-TOM
Ensuite, pour les deux tours, nous modifions les codes départements contenant des caractères et correspondant aux DOM-TOM. Nous mettons soit le département 97, 98 ou 976
e) Correspondance avec le code INSEE pour chaque commune
Nous avons récupéré les codes INSEE et le but ici est de réunir les informations entre nos tables du tour 1 et tour 2 et le taux d'abstention pour chaque code INSEE.
# Nous avons récupéré les codes de l'INSEE correspondant à chaque commune
codes_postaux2 <- read.csv("codes_postaux2.csv", sep=";", header=TRUE)
# Premier tour
# Jointure de deux tables concernant le premier tour, les résultats et les indicatifs géographiques
tour1 <- merge(codes_postaux2,data_1tour_2, by = intersect(names(data_1tour_2), names(codes_postaux2)))
# ajout de la colonne "taux d'abstention"
tour1bis <- cbind(tour1,(tour1[,19]/tour1[,18])*100)
# Deuxième tour
# Jointure de deux tables concernant le deuxième tour, les résultats et les indicatifs géographiques
tour2 <- merge(codes_postaux2,data_2tour_2, by = intersect(names(data_2tour_2), names(codes_postaux2)))
# ajout de la colonne "taux d'abstention"
tour2bis <- cbind(tour2,(tour2[,19]/tour2[,18])*100)
Cliquer ici pour voir le code.
2- Représentation graphique du taux d'abstention en France pour les élections municipales
Ici, nous affichons pour les deux tours des élections la carte de la
France représentant le taux d'abstention pour chaque commune.
Vous
pouvez retrouver le code ici


Pour le premier tour des élections, nous remarquons un fort taux
d'abstention dans les communes d'Ile de France, du sud-est qui bordent
la méditerranée et le littoral ouest.
Par contre, dans les régions
du Limousin et Auvergne, un faible taux d'abstention est observé.
Nous pouvons aller plus loin, en disant qu'une tendance se dessine par
département.
Pour le deuxième tour des élections, nous avons moins de données mais nous distinguons quand même la même tendance qu'au premier tour.
3- Représentation graphique du taux d'abstention en France pour les élections cantonales 2008
a) Représentation graphique, découpage par commune
Les élections cantonales en 2008 se sont déroulées aux mêmes dates que les élections municipales. C'est pourquoi, il est intéressant de voir s'il y a un lien entre les taux d'abstention de ces deux élections.
Ici, nous affichons pour les deux tours des élections cantonales la carte de la France représentant le taux d'abstention pour chaque commune.


Même si nous ne disposons pas de toutes les données pour les élections cantonales, nous remarquons la même tendance pour les deux élections au premier tour.
La comparaison n'est pas possible pour le deuxième tour.
b) Etude des corrélations entre les taux d'abstention des élections cantonales et municipales pour le premier tour
Nous allons étudier s'il y a une corrélation entre les deux taux d'abstention.
Pour cela, nous avons d'abord effectué un test de Pearson.
Le test de Pearson teste l'hypothèse nulle: les variables ne sont pas corrélées. On fixe le seuil à 5%. Après application du test, voici la sortie R.
Nous remarquons que notre p-value est largement en-dessous de 0.05 (2.2e-16) donc nous prenons un très faible risque à rejeter l'hypothèse nulle ce qui signifie que nos variables sont très corrélées. De plus, nous avons un coefficient de corrélation d'environ 0.95.
Ensuite, nous avons fait une régression linéaire pour montrer le
résultat précédent en prenant comme variable à expliquer le taux
d'abstention aux cantonales et comme variable explicative le taux
d'abstention aux municipales.
Nous représentons ci-dessous le nuage
de points (les communes) avec la droite de régression superposée par
dessus en rouge.
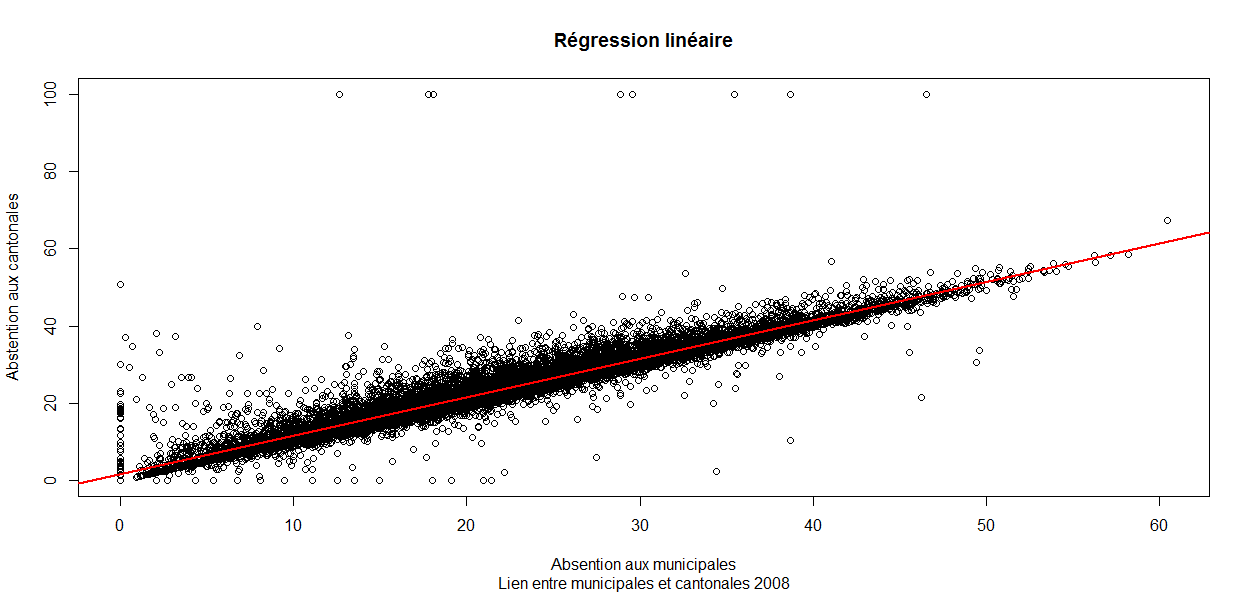
Cette régression appuie le fait que ces deux variables sont très liées
puisque la majorité des communes se concentrent autour de la
droite.
Probablement dû au fait que ces élections se soient
déroulées le même jour, pour une commune donnée, l'abstentionnisme est
quasiment le même pour les deux élections.
Vous pouvez retrouver le code de cette partie ici
4- Taux d'abstention comparé à des indicateurs économiques et sociaux
Dans cette partie, nous prenons le taux d'abstention obtenu au
premier tour des élections municipales.
Grâce à un regroupement des données par département, nous obtenons une tendance nationale pour le premier tour pour chacun des indicateurs étudiés. Nous allons essayer de voir si une corrélation existe entre le taux d'abstention et les indicateurs économiques et sociaux au niveau national.
a) Pourcentage de résidences principales

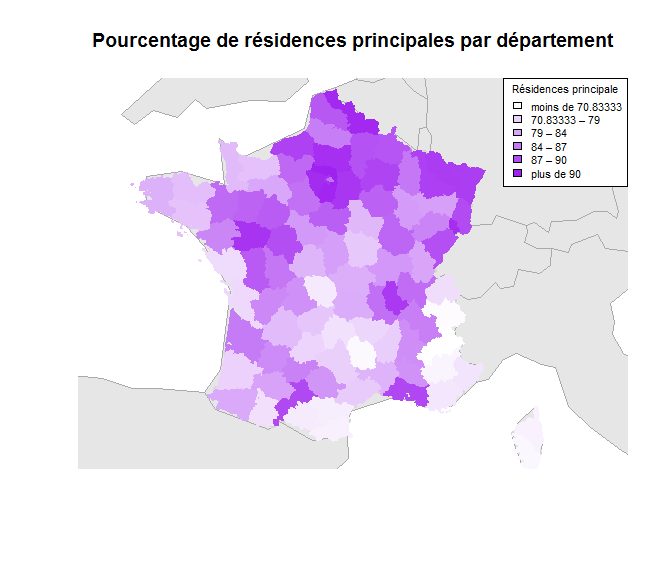
Nous observons les mêmes variations sur les deux cartes, ceci nous permet de suggérer qu'il y a une corrélation entre le taux d'abstention et le pourcentage de résidences principales. Il existe donc un lien entre le pourcentage de personnes ayant une résidence principale et le taux d'abstention. Il semblerait que plus un département a d'habitants ayant une résidence principale, plus l'abstention y sera forte. Par extension on peut conjecturer que plus une zone est peuplée d'habitants à l'année, plus l'abstention sera élevée.
Lien vers le code utilisé pour traiter le pourcentage de résidence par département.
b) Pourcentage de logements vacants

D'après les cartes, nous pouvons remarquer que le pourcentage de
logements vacants évolue en opposition avec le taux d'abstention.
Par exemple, au centre de la France où le taux d'abstention y est le
plus bas, le pourcentage de logements vacants y est le plus élevé. A
contrario, en Ile de France, le pourcentage de logements vacants est
assez bas par rapport aux autres départements, pour un taux d'abstention
de plus de 30% en moyenne, un des plus hauts de France.
Lien vers le code utilisé pour traiter le pourcentage de logements vacants par département.
c) Taux de chômage

Le lien entre le taux de chômage et le taux d'abstention est difficile à
voir, cependant on peut faire des observations. Ces deux données
semblent suivre les mêmes variations pour la majorité des
départements.
Par exemple, il s'avère que dans le centre de la
France, dans les départements où le taux de chômage est le plus bas,
l'abstention y est aussi la plus basse en France.
En Ile de France,
Nord-Est et sur la côte méditerranéenne, les taux surfent sur la même
tendance.
Lien vers le code utilisé pour traiter le taux de chômage par département.
d) Pourcentage de personnes payant l'ISF

Il nous est difficile de mettre en évidence un quelconque lien entre
l'abstention et le pourcentage de personnes redevables à l'ISF. Surtout
que dans certains départements comme l'Ardèche et l'Ariège, personne
n'est redevable à l'ISF (ou nous manquons d'informations).
Nous ne
garderons pas la variable pourcentage de redevables à l'ISF pour la
suite de l'étude, du fait du peu de corrélation évidente avec le taux
d'abstention.
Lien vers le code utilisé pour traiter le pourcentage de personnes redevables à l'ISF.
e) Etude des corrélations
Pour appuyer, ou non, les conclusions que l'on a tirées des cartes, voici un tableau récapitulatif des corrélations entre les différentes variables.
Le graphique se lit grâce à l'échelle de couleurs sur la droite. Plus le cercle est gros, plus la teinte est foncée, plus le coefficient de corrélation entre les deux variables est proche de 1 pour la couleur bleu et proche de -1 pour la couleur rouge foncée.
Rappelons que plus un coefficient de corrélation est proche de 1 ou de -1, plus les deux variables sont corrélées positivement ou négativement.
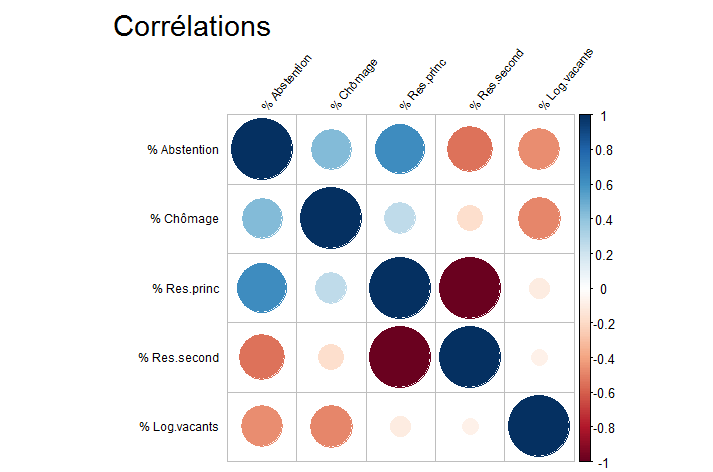
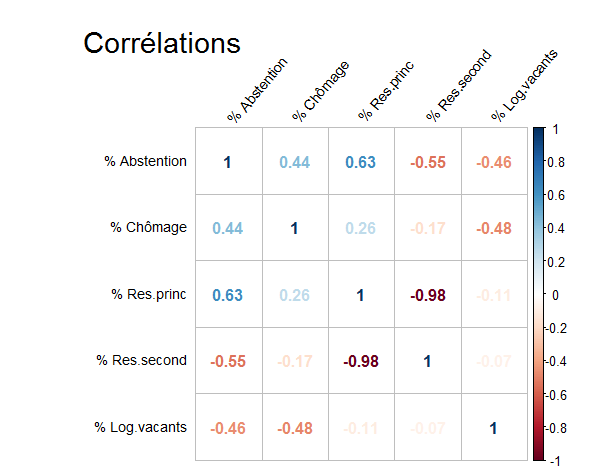
Nous remarquons qu'en effet, c'est le pourcentage de résidences
principales qui est le plus corrélé avec le taux d'abstention
(coefficient de 0.63).
Les autres coefficients de corrélation de la
première colonne permettent quand même de mettre en évidence que les
variables: taux de chômage, pourcentage de résidences secondaires et
pourcentage de logements vacants sont corrélées au taux
d'abtention.
Il existe donc un lien tout de même entre le taux
d'abstention et ces différentes variables.
De plus, ce graphique permet de mettre en évidence la forte corrélation entre le pourcentage de résidences principales et le pourcentage de résidences secondaires, ce qui est logique puisque ces chiffres sont complémentaires pour chaque département.
Lien vers le code utilisé pour afficher les corrélations.
f) Régressions linéaires
Nous allons faire une régression linéaire par commune et une régression linéaire par département en prenant comme variable à expliquer l’abstention et comme variables explicatives : le taux de chômage, le pourcentage de logements vacants, le pourcentage de logements principales et le pourcentage de logements secondaires.
Le coefficient de détermination est un coefficient qui est compris entre 0 et 1. Plus le coefficient est proche de 1, plus l'équation de la droite de régression est adaptée pour décrire la distribution des points, c'est-à-dire la distribution des communes (ou des départements).
Pour les communes et départements, plus les points sont regroupés autour de la droite, plus notre variable taux d'abstention est bien expliquée par les autres variables (taux de chômage, pourcentage de logements vacants, pourcentage de logements principales et pourcentage de logements secondaires).
Le test de Fisher permet de tester la significativité globale d'un modèle. La réponse est négative si H0 est acceptée : la pente de la droite de régression est nulle, le nuage de point est réparti sans structure linéaire significative. La réponse est positive lorsque le test est significatif et donc l’hypothèse H0 rejetée.
- Régression linéaire par commune
Nous avons ici un coefficient de détermination d'environ 0.87 (Multiple
R-squared). Cela signifie que la droite de régression est capable de
déterminer 87% des points.
Ici, la statistique F est égale à
5.86e+04 et la p-valeur est proche de 0 (2.2e-16), nous rejetons alors
l'hypothèse nulle, avec un seuil de 5% sans risque aucun.
Donc le modèle est significatif, le taux d’abstention est bien représenté par les autres variables.
De plus, en regardant les p-valeurs associées à chacune des variables, dans le test de Student de nullité des coefficients, elles sont bien toutes inférieures à 0.05. On conclut que tous les coefficients sont bien différents de zéro et que donc, chaque variable est bien représentée.
- Régression linéaire par département
Ici, le coefficient de détermination est de 0.98. Donc la droite de régression est capable de déterminer la quasi-totalité des points.
Pour le test de Fisher, nous avons une statistique F égale à 1182 et une p-valeur proche de 0 (2.2e-16). Donc comme précédemment, nous rejetons l'hypothèse nulle, le modèle est globalement significatif. Donc le taux d'abstention est convenablement expliqué par les autres variables.
En revanche, en observant les résultats du test de Student, test sur la nullité des coefficients, nous remarquons que pour les variables taux de chômage et pourcentage de résidences secondaires, les p-valeurs sont supérieures à 0.05. Pour les coefficients associés à ces deux variables, l’hypothèse de nullité n’est pas rejetée (seuil de 5%), ces variables sont probablement moins bien représentées dans le modèle.
Lien vers le code utilisé pour afficher les régressions.
Conclusion
Nous avons donc mis en évidence le lien entre le taux d’abstention et d’autres variables socio-économiques.
Durant notre projet, nous avons montré que par département les deux variables qui sont liées avec l'abstention sont le pourcentage de résidences principales et le pourcentage de logements vacants. Plus il y a de résidences principales dans le département plus il y a d'abstentions mais plus il y a de logements vacants et moins il y a d'abstentions.
Le taux d'abstention peut être expliqué par beaucoup d'autres facteurs aussi, comme la météo, les événements extérieurs (sportifs, politique...).
Vous pouvez retouver ici les tableaux que nous avons modifiés:
- Elections municipales par commune au premier tour
- Elections municipales par commune au deuxième tour
- Le taux d'abstention des élections cantonales par commune
- Abstentions par département
- Chômage par département
- Le type de logements par département
- Le nombre de personnes redevables par département
- Abstentions par commune
- Chômage par commune
- Le type de logements par commune
Références:
https://www.data.gouv.fr/fr/
http://ants.builders/blog/18-02-2014/predicting-abstention-rate-using-open-data.html
https://www.data.gouv.fr/fr/datasets/elections-municipales-2008-resultats-572150/
http://www.insee.fr/fr/bases-de-donnees/default.asp?page=statistiques-locales/donnees-detaillees
tableau.htm