Analyse textuelle et prédiction de parti politique
Twitter a été créé le 21 mars 2006 par Jack Dorsey, Evan Williams, Biz Stone et Noah Glass, et lancé en juillet de la même année. C'est un réseau social permettant de publier de courts messages de moins de 140 caractères. En utilisant l'API disponible, il est possible de récupérer toutes les informations publiques disponibles. Nous allons essayer d'utiliser cette API pour prédire l'appartenance d'un compte à un parti politique parmi :
- le Front National,
- les Républicains,
- le Parti Socialiste,
- le Parti de Gauche.
Récupération des données
Pour récupérer les données, nous utilisons l'API Twitter grâce au package twitteR. Pour nous connecter à cette API, il faut se créer un compte développeur pour obtenir des clès d'accès. Ensuite, on s'identifie auprès de l'API grâce à la fonction setup_twitter_oauth
library(twitteR)
api_key = "k7eTg9kLlKqtYsabG1b0K9fLE"
api_secret = "z7lqGkKrHwrzcXNpXF9wIogqgz48izWMLpXxrVpTzJ53obTCi1"
access_token = "4783824278-TPEVSp51eRIE3DmXkVEOEKqzDT2Mvda0rZl5rSZ"
access_token_secret = "jJ41j8Az0tJIk8TaU7zFxSFk51gCT3i0GiVEhgQL1oFhN"
setup_twitter_oauth(api_key,api_secret,access_token,access_token_secret)
## [1] "Using direct authentication"
Il est maintenant possible de récupérer des informations de comptes publiques ou de tweets par recherche de mot-clé ou par compte.
# Récupération du compte de François Hollande
fh = getUser("fhollande")
# Récupération d'un tweet de François Hollande
userTimeline(fh,n=1)
## [[1]]
## [1] "fhollande: Les #JOJ2016 viennent de s'ouvrir à #Lillehammer. Bonne chance à nos jeunes de l'équipe de France ! @jeuxolympiques"
# Récupération d'un tweet possédant le mot France en français
searchTwitter("France",n=1,lang="fr")
## [[1]]
## [1] "sadabeef: RT @beinsports_FR: Ronaldo en direct sur beIN SPORTS : \"Le PSG a mieux joué. Mais tout est possible en Champions League !\" #PSGCHE https://…"
Pour pouvoir faire du machine learning, il nous faut des données d'apprentissage. Nous allons utiliser des tweets postés par les comptes suivants :

Traitement des données
Pour pouvoir faire de l'analyse textuelle sur des tweets, il faut commencer par les rendre exploitables. Voici un exemple de tweet.
## $text
## [1] "Pour #Valls, Matignon vaut bien une messe http://t.co/ApIzhNBC7S via @wordpressdotcom"
Pour commencer, il va falloir supprimer toutes les informations inutiles telles que les @comptes, les #Hashtags, les liens... Ensuite, il faut supprimer toute la ponctuation, les accents, mettre le texte en minuscule et supprimer les espaces en trop. Pour faire ces modifications, on utilise principalement le fonction gsub. On obtient alors ceci :
## [1] "pour matignon vaut bien une messe"
Fonctions de nettoyage de tweets
Création de la table d'apprentissage
Avant d'arriver à la phase d'apprentissage, il faut se créer une table utilisable. Pour l'instant nous n'avons que les textes des tweets nettoyés. Il va donc falloir transformer ces textes en table. La première étape consiste à enlever ce qu'on appelle les mots vides (stop words en anglais). Ce sont des mots tellement communs qu'ils n'apportent aucune information. Dans le package tm, il existe une fonction removeWords qui supprime ces mots.
library(tm)
removeWords(tweet_propre,stopwords("french"))
## [1] " matignon vaut bien messe"
Grâce au package tm, il est aussi possible de créer un corpus, c'est à
dire un ensemble de document, puis de générer une table où chaque ligne
est un mot apparaissant dans le corpus, chaque colonne est un document
du corpus et indiquant le nombre d'apparition de chaque mot dans chaque
document.
En utilisant cette méthode, nous obtenons une table
contenant 24 572 mots pour 34 312 tweets. Le problème est qu'en moyenne
il y a 7 mots différents par tweet (une fois nettoyé), ce qui représente
environ 0.03% de l'ensemble des mots différents du corpus.
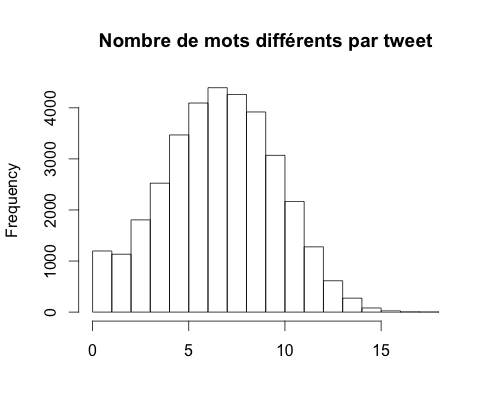
Afin de limiter ce problème, il est possible de regrouper plusieurs tweets et les considérer comme un seul. Dans la suite, nous allons donc regrouper les tweets d'un parti (compte officiel + comptes des personnes politiques) par 100. Nous obtenons alors 340 groupes possédant en moyenne 567 mots différents par groupes, soit environ 2,3% de l'ensemble des mots différents du corpus.
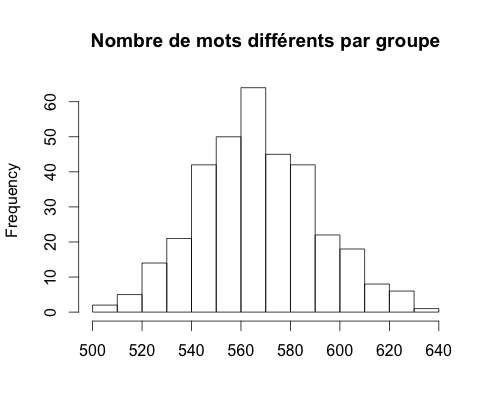
Pour finir, il faut transformer la table en table des fréquences (le nombre de mots par tweet étant diférent d'un groupe à l'autre) et la transposer, les variables explicatives étant les mots et non les groupes.
Apprentissage
Première ACP
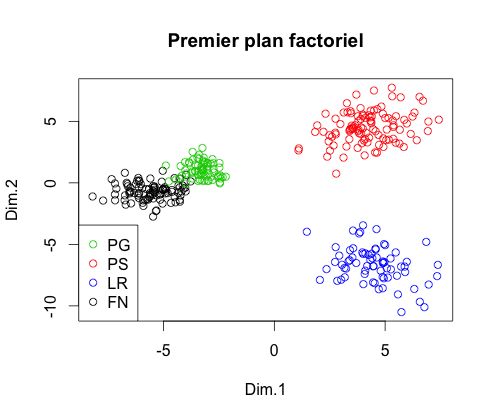
Maintenant que nous avons une table exploitable, il faut effectuer une ACP afin de diminuer le nombre de variables explicatives dans le but de diminuer le temps d'exécution. Suite à cette ACP, on obtient les trois premiers plans factoriels
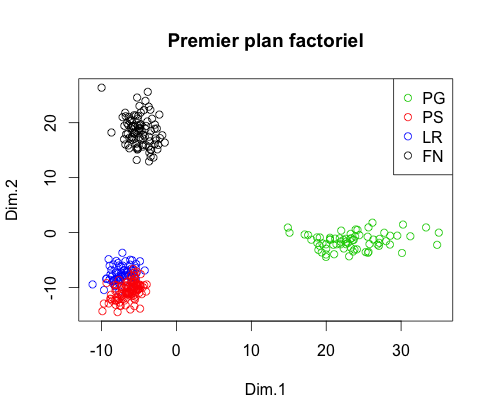
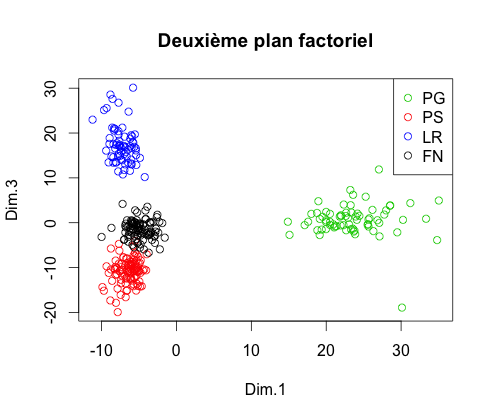
On constate que dans l'espace composé des trois premiers axes factoriels, chaque groupe est séparé des autres. Pour en être certain, on peut effectuer une Classification Ascendante Hiérarchique et obtenir le dendrogramme
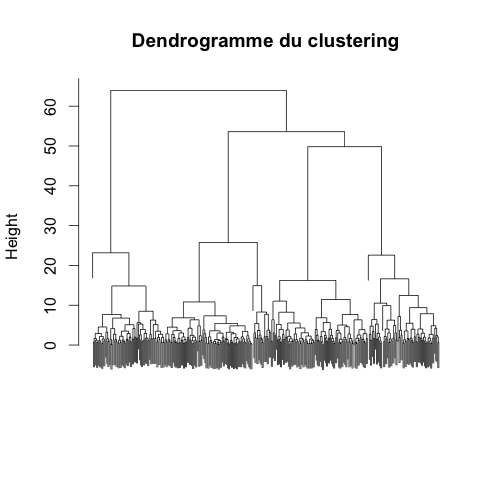
On observe bien une séparation en quatres classes. En les comparant aux
classe réelles, on constate qu'aucun groupe n'a été mal classé. On en
déduit qu'une projection sur cet espace pourrait être suffisant pour
prédire correctement l'appartenance à un parti, et que dans l'espace de
départ, les classes sont vraiment très éloignées.
Cependant, nous
sommes toujours face au problème du nombre de variables. L'enjeu va donc
être de réduire ce nombre tout en gardant un espace utilisable.
Réduction de variables
Pour réduire le nombre de variables, il est possible de regarder celles qui ont la plus grande contribution. Nous récupérons donc, pour chaque axe, le vecteur des variables qui ont des contributions supérieures à la moyenne puis nous ne gardons que l'intersection de ces trois vecteurs. Cela nous permet de passer de 24 475 mots à 547. Effectuons une seconde ACP pour voir si la projection nous donne encore quatre classes bien distinctes.
Seconde ACP
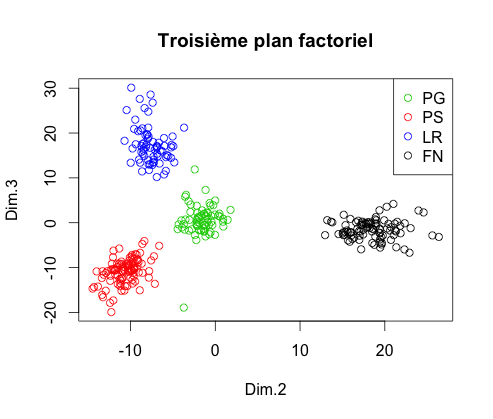
Suite à cette nouvelle ACP, on observe les nuages de points sur les trois premiers plans factoriel :
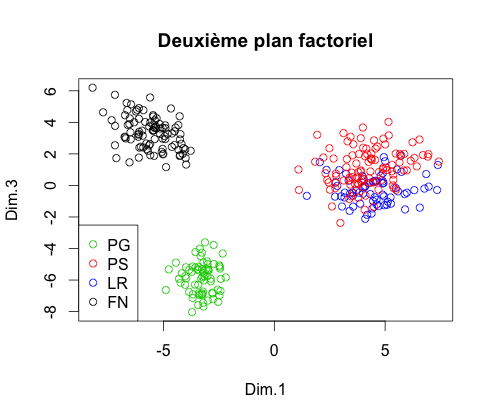
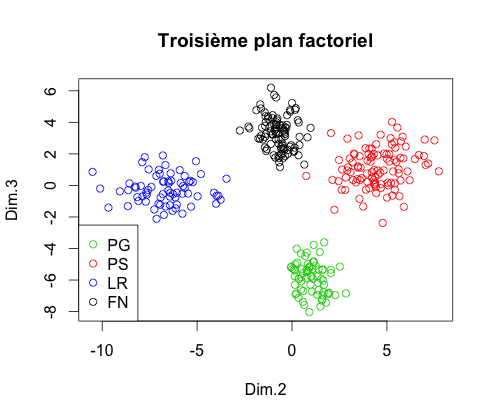
Il semble de nouveau que dans l'espace composé des trois premiers axes factoriels, la projection permette une prédiction efficace. En effectuant une nouvelle CAH, on obtient le dendrogramme :
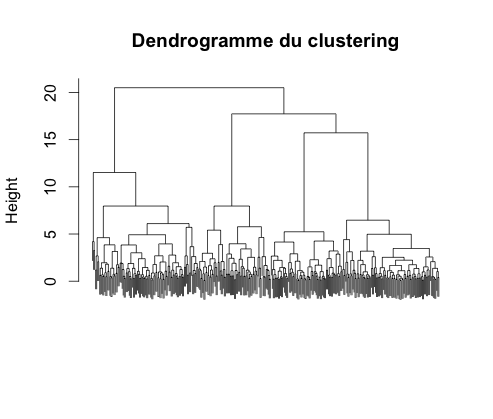
Comme précédemment, la classification nous donne quatre classes mais elles sont moins éloignées. Or, dans l'espace des 547 mots, la distance entre chaque classe est pire égale à celle dans l'espace des trois premiers axes factoriels, au mieux beaucoup plus espacés. Par conséquent nous allons faire de la classification sur l'espace à 547 mots.
Choix du classifieur
Maintenant que le nombre de variables a été réduit, il nous faut déterminer le meilleur classifieur possible. Étant donné l'écart qu'il y a entre les quatre classes dans l'espace, calculer une erreur à partir des données d'apprentissage n'est pas très pertinent. Il faut donc calculer cette erreur en utilisant de nouvelles données. Nous allons donc récupérer les tweets des comptes suivants et les nettoyer comme pour les comptes d'apprentissage :

Les classifieurs comparés dans la suite seront :
- k-plus proches voisins avec k entre 5 et 50 par pas de 5,
- Analyse Linéaire Discriminante,
- Support Vector Machine avec un noyau linéaire, polynômial (degré 2,3,4,5), gaussien et sigmoïdal.
On calcule l'erreur de prédiction de chacun de ces classifieurs cinquante fois puis on représente les boxplot obtenus.
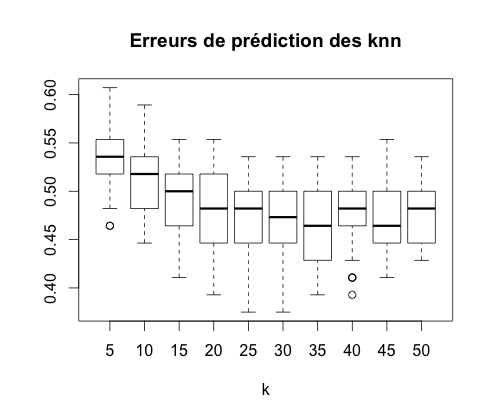
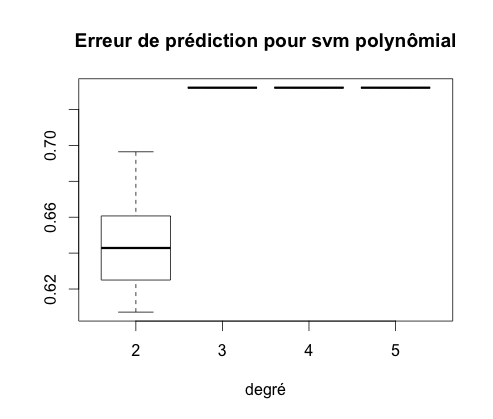
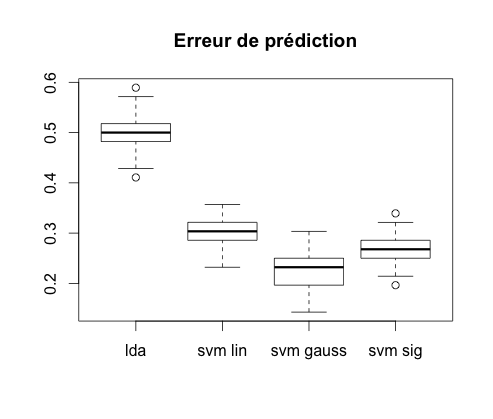
On constate que le meilleur de ces classifieurs est le SVM à noyau gaussien avec une erreur moyenne de 27%.
Prédiction sur des comptes non politisés
Ayant déterminé quel classifieur utilisé, regardons quel pourrait être le résultat d'une classification d'un compte non politisé. Par exemple, prenons le compte d'Alexandre Astier (@sgtpembry) et observons le résultat de la prédiction.
prediction("sgtpembry")
## [1] "PG"
Bien que la fonction prediction nous donne un parti pour Alexandre Astier, cette prédiction n'est pas particulièrement pertinente étant donné que seul 26 des mots utilisés dans ses tweets sont utilisés pour la classification.
Conclusion
De façon assez étonnante, nous avons constaté qu'il était possible de
prédire plus ou moins bien l'appartenance d'un compte à un parti
simplement en analysant les mots utilisés dans ses tweets. Cependant,
plusieurs améliorations sont possibles.
Pour commencer, nous aurions pu pousser le nettoyage des textes plus
loin en ajoutant une étape de
racinisation,
c'est à dire transformer chaque mot en sa racine afin d'éviter de
considérer "étape" et "étapes"comme deux mots différents (algorithme de
Porter ou algorithme de Carry).
Nous aurions aussi pu prendre en compte les hashtags et comptes cités
dans les tweets, ou même intégrer les retweets parmi les tweets d'une
personne.
Par la suite nous aurions pu regarder si le classifieur actuel est
valable dans le passé et s'il le sera dans le futur car les mots retenus
sont peut être des mots d'actualité.
Enfin, il pourrait être intéressant d'utiliser cette classification pour essayer de prédire des résultats à des élections, par exemple l'élection présidentielle de 2012 avec des tweets d'époque pour vérifier l'efficacité de cette classification et voir si Twitter peut être un bon moyen d'effectuer des sondages.