Prévision du taux d’abstention aux élections municipales
Valentin MONFEUGA & Joseph BITAR
Sommaire
I. Calcul et représentation du taux d'abstention
1. Première introduction au sujet
2. Importation des données
3. Traitements des données
4. Représentation sur la carte
II. Variables socioéconomiques et sociodémographiques influentes dans
le taux d'abstention
1. Présentation des données
2. Importation des données
3. Regroupement des tables
4. Sélection des variables par la méthode backward
5. Interprétation de la sélection des variables
III. Etude du lien linéaire ou non linéaire du taux d'abstention avec
les variables sélectionnées
1. Corrélation
2. Représentation graphique des variables les plus
corrélées
IV. Prévision du taux d'abstention
Conclusion
Références
I. Calcul et représentation du taux d'abstention
Le but de ce projet informatique est de s’intéresser à la prévision du taux d’abstention aux élections municipales de 2008 en France par un traitement de données libres qui utilise des méthodes de statistiques descriptives et inférentielles vues tout au long de notre formation. Les données de ce projet sont en accès libre sur Internet sur des sites de données publiques.
1. Première introduction au sujet
Voici les liens utiles à l'importation des données :
Les résultats des élections dans toutes les communes de France, se trouvent découper en 3 parties
- On a tout d'abord les résultats d'élections municipales, tours 1 et 2, pour les communes de moins 3500 habitants des départements 1 à 48 et outre-mer.
- Ensuite on retrouve les résultats d'élections municipales pour les communes de moins de 3500 habitants des départements 49 à 95
- Enfin on a les résultats d'élections municipales pour les communes de plus de 3500 habitants.
Ces différents fichiers sont des fichiers Excel, donc au format .xls or pour nous permettre de lire les fichiers sur notre logiciel Rstudio, il nous faut convertir ces différentes tables au format .csv (Cette étape fût réaliser directement grâce à Excel).
2. Importation des données
Dans un premier temps nous allons importer les données fournies par l'administration française. Le code utilisé lors de l'importation des données se trouve ici. Nous n'utiliserons que certaines variables sur ces différentes tables, tels que le code commune, le code département, le nombre d'inscrits, et le nombre d'abstention. Cette étape de choix de variables se fera dans la partie suivante.
3. Traitements des données
- Ensuite nous allons récuperer seulement les variables qui nous sont nécessaires.
- Nous allons réunir les différentes communes de moins de 3500 habitants en une seule table et ensuite différenciés le tour 1 et le tour 2. Nous allons construire 2 grandes tables pour chaque tour avec toutes les communes.
- Nous avons décidé de ne pas inclure les données des départements d'outre-mer. Et nous allons ensuite nettoyer la table, pour rendre les codes communes conforme aux codes INSEE qui nous serviront plus loin lors de la représentation sur la carte de France Métropolitaine.
- Par soucis de temps de calcul, nous avons enregistrer cette table sous forme csv et ensuite ne pas avoir besoin de relancer la partie supérieur à chaque modification du code.
Pour étudier notre code de cette deuxième partie veuillez vous référer à ce lien.
4. Représentation sur la carte
De même nous allons vous afficher une image qui est le résultat obtenu sur nos machines. Le temps de calcul est trop long et certaines librairies ne peuvent être lues sur linux. Pour obtenir le code nécessaire à l'affiche de la carte ci dessous, veuillez cliquer ici.

II. Variables socioéconomiques et sociodémographiques influentes dans le taux d'abstention.
Après avoir représenté graphiquement le taux d'abstention sur le territoire français, nous souhaitons savoir quelles sont les variables qui influent ce taux d'abstention.
1. Présentation des données
Pour les catégories socioéconomiques et démographiques, nous avons notamment utilisé le recensement réalisé en 2012 dont on avait accès grâce à l'INSEE. Il nous permet d'obtenir de nombreuses données par rapport à des thèmes très variés.
Voici les différentes tables que nous avons utilisé :
logement : logements, résidences principales, résidences secondaires et logements occasionnels, logements vacants, maisons, appartements
fonction : quantification des fonctions et des cadres des fonctions métropolitaines pour toutes les communes
formation : structure par sexe et âge de la population scolarisée et population de 15 ans ou plus non scolarisée selon le diplôme le plus élevé obtenu
etablissement : principaux indicateurs sur les établissements actifs
nombre d'établissement : nombre d’établissements par secteur d’activité
taille d'établissment : nombre d'établissement par taille
population : évolution et structure de la population
ménages : données sur les couples, familles et ménages
population active : structure de la population résidente des 15 à 64 ans selon sa situation d’activité ; caractéristiques des emplois au lieu de travail
emploi : données sur la population de 15 ans ou plus ayant un emploi selon le statut, la condition d'emploi, la durée de travail et le lieu de travail.
Nous précisons que nous n'avons pas pris en compte les communes d'outre-mer puisque dans certaines bases de données pour les variables socioéconomiques et sociodémographiques, ces communes n’en faisaient pas parties. De plus, la carte que nous avons réalisé précedemment représente uniquement la France métropolitaine.
2. Transformation des variables
Pour chaque variable, nous l’avons transformée en pourcentage. Par exemple, pour la variable nombre de personnes âgées entre 30 et 45 ans, elle a été divisée par la population totale de la commune concernée pour en obtenir le pourcentage de personnes âgées entre 30 et 45 ans sur chaque commune.
La transformation de chaque table se trouve ici.
3. Regroupement des tables
On regroupe alors l’ensemble des variables qui contiennent toutes des pourcentages auxquelles on ajoute le taux d’abstention qui a été calculé précédemment. On utilise les pourcentages plutôt que les quantités exactes dans chaque commune par rapport aux variables, car cela est plus représentatif par rapport à l’ensemble de la commune. Nous nous sommes servis du code insee pour regrouper les 2 tables, celle contenant le taux d’abstention et celle contenant toutes les variables socioéconomiques et démographiques. En effet, certaines villes ne sont pas écrites de la même manière dans les deux tables alors qu’avec le code insee, nous n’avons pas ce problème.
Au final, nous avons 35890 observations avec 496 variables. Nous avons au final un grand nombre de données puisque nous avons 17 801 440 données.
Le regroupement des tables s'est réalisé à partir du code qui se trouve ici.
4. Sélection des variables par la méthode backward
On réalise une sélection de variables à partir des p-valeur des variables du modèle. En effet, on ne sélectionne uniquement les variables qui ont une p-valeur inférieure à 5%, c'est-à-dire les variables qui sont le plus significatives. Nous avons utilisé donc une méthode de sélection de variables qui est la méthode de sélection backward. Cette méthode consiste à localiser la variable avec la p-valeur la plus élevée et la retirer du modèle. Au final, il nous reste 69 variables avec des p-valeur inférieur à 0.05, qui vont nous permettre d'expliquer le taux d'abstention.
Le code qui nous a permi de réaliser cette sélection de variables se trouve ici.
5. Résultats de la sélection des variables
Après avoir réalisé la sélection backward, nous obtenons 69 variables. En effet, nous avons :
- 18 variables en rapport avec le logement
- 14 variables sur le thème de l'éducation-enseignement
- 26 variables sur les entreprises
- 3 variables en rapport avec la population
- 8 variables sur le thème du travail et de l'emploi.
Pour visualiser la liste de l'ensemble des variables sélectionnées nous avons réalisé un tableau structurant les variables sélectionnées par thème.
On constate que les variables les plus présentes sont celles autour du logement, de l'éducation et des entreprises. Cependant, il ne faut pas négliger les variables autour de la structure de la population, même si elles ne sont qu'au nombre de 3.
De plus, un nombre important de table de données n'ont pas été retenu dans la sélection des variables car aucune variable de ces tables n'a été sélectionnée. Il s'agit des tables principalement axées sur l'emploi et sur les entreprises :
fonction : quantification des fonctions et des cadres des fonctions métropolitaines pour toutes les communes
etablissement : principaux indicateurs sur les établissements actifs
nombre d'établissement : nombre d’établissements par secteur d’activité
taille d'établissment : nombre d'établissement par taille
emploi : données sur la population de 15 ans ou plus ayant un emploi selon le statut, la condition d'emploi, la durée de travail et le lieu de travail.
4 variables en rapport avec les entreprises agricoles sont sélectionnées
: Etablissements actifs de l’agriculture, sylviculture et pêche,
Etablissements actifs de l’agriculture, sylviculture et pêche 1 à 9
salariés,Etablissements actifs de l’agriculture, sylviculture et pêche
de 10 à 19 salariés, Pourcentage de postes des établissements actifs de
l’agriculture, sylviculture et pêche.
4 variables en rapport avec les entreprises industriels sont
sélectionnées : Etablissements actifs de l’industrie, Etablissements
actifs de l’industrie de 1 à 9 salariés, Pourcentage de postes des
établissements actifs de l’industrie, Pourcentage de postes des
établissements actifs de l’industrie de 10 à 19 salariés.
III. Etude du lien linéaire ou non linéaire du taux d'abstention avec les variables sélectionnées
1. Corrélation
Afin d'étudier l'intensité de liaison qui peut exister entre le taux d'abstention et les variables retenues, nous allons étudier leurs corrélations.
La mesure de corrélation linéaire entre deux variables se fait alors par le calcul du coefficient de corrélation linéaire. Il est compris entre -1 et 1. Plus le coefficient est proche des valeurs extrêmes -1 et 1, plus la corrélation entre les variables est forte. Une corrélation égale à 0 signifie que les variables ne sont pas corrélées.
Nous avons décider d'afficher les 6 variables qui ont le coefficient de corrélation le plus fort.
# Variables qui ont le coefficient de corrélation le plus fort
order(abs(cor(final.lm,method = "spearman")[,70]),decreasing = T)
cor(final.lm[,c(70,9,17,69,1,8,23)],method = "spearman")[,1]
Nous obtenons alors comme coefficient de corrélation pour ces 6 variables :
- Pourcentage de résidences principales construites de 1946 à 1990 : 0.4558987
- Pourcentage de personnes des résidences principales HLM louées vides : 0.4072922
- Pourcentage d'actifs occupés de 15 ans ou plus utilisant les transports en commun pour aller travailler : 0.3828975
- Pourcentage de résidences secondaires et logements occasionnels : -0.3826803
- Pourcentage de résidences principales construites avant 2010 : 0.3725497
- Pourcentage d'hommes de plus de 30 ans : -0.3724158
On constate que ces 6 coefficients de corrélation sont tous faibles.
2. Représentation graphique des variables les plus corrélées
Pour s'assurer de ces résultats, nous avons décidé de représenter graphiquement le taux d'abstention en fonction de ces variables avec ce code pour la représentation graphique.
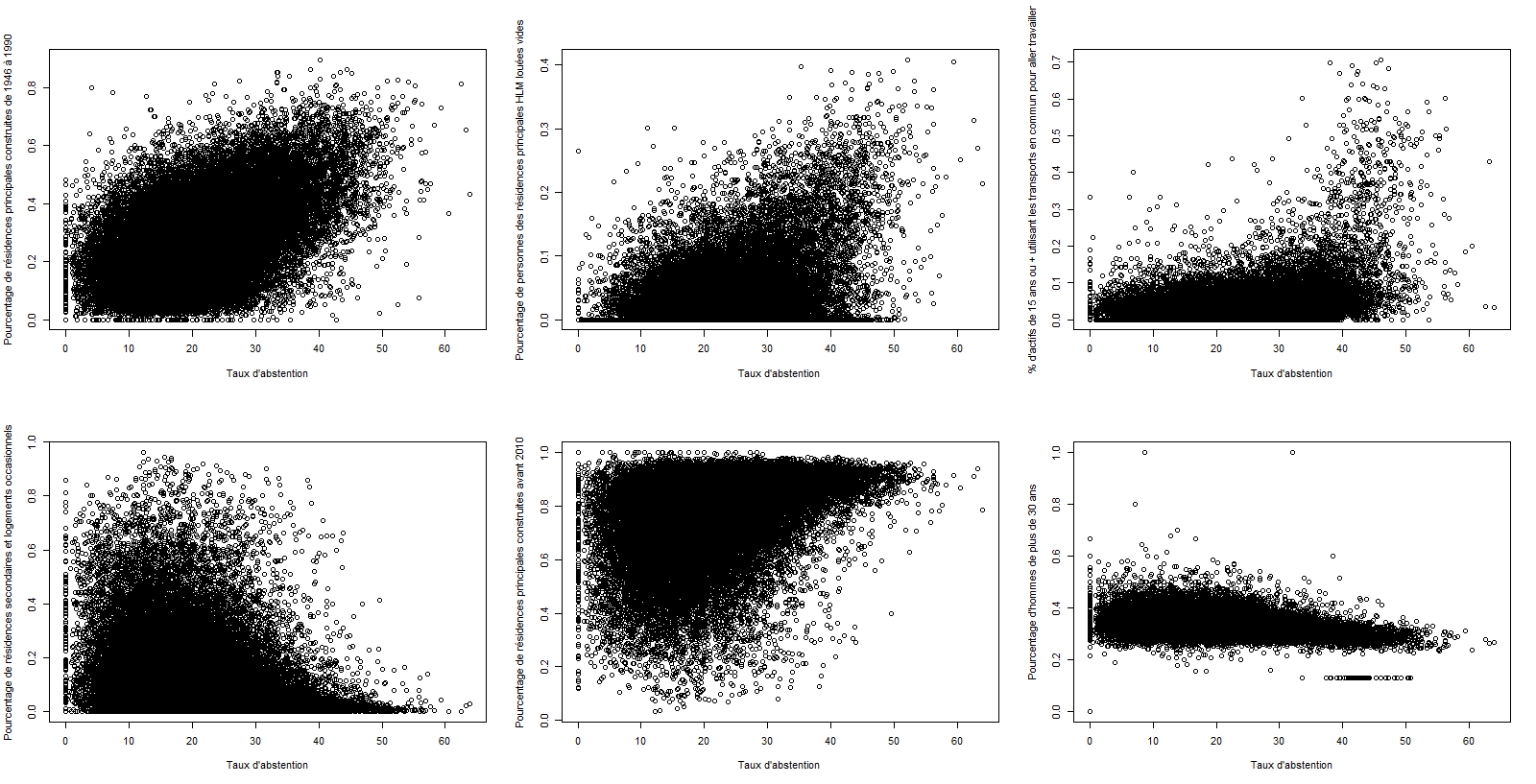
On remarque bien que le lien est non linéaire entre le taux d'abstention et ces variables.
IV. Prévision du taux d'abstention
Avec le modèle obtenu dans la partie précédente nous allons essayer de prévoir le taux d'abstention des éléctions municipales de 2008, de la nouvelle région Aquitaine-Limousin-Poitou-Charente.
Nous avons utilisé un randomForest pour faire notre régression, pour cela nous avons donc diviser notre table en 2 parties :
- un premier groupe d'apprentissage, qui correspond à toutes les communes en dehors de la région Aquitaine-Limousin-Poitou-Charente,
- et le deuxième groupe qui sera le groupe test, donc toutes les communes de la région Aquitaine-Limousin-Poitou-Charente.
Pour voir comment nous avons fait cette prédiction, veuillez vous référer à ce lien.
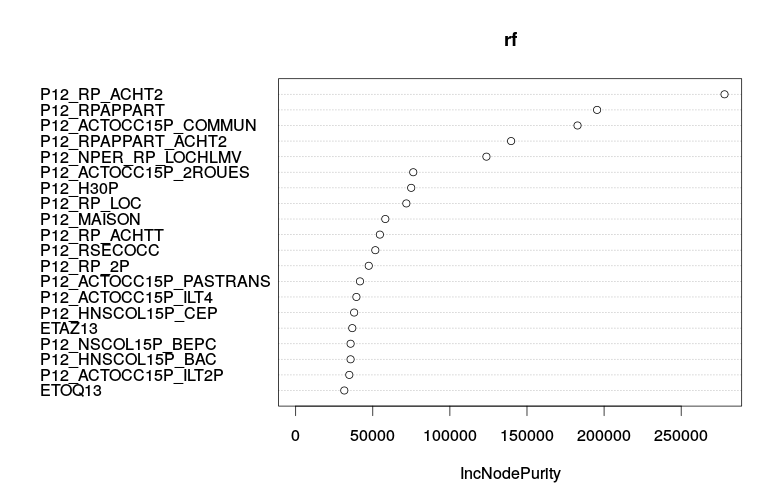
On peut voir, ci dessous, quelles ont été les variables les plus discriminantes dans notre régression grâce à la fonction varImpPlot() du package randomForest.
Voici une comparaison graphique de la région entre les vraies valeurs et les valeurs prédites du taux d'abstention grâce à notre modèle.
Carte de la région Aquitaine-Limousin-Poitou-Charente représentant le taux d'abtention réel des élections municipales en 2008

Carte de la région Aquitaine-Limousin-Poitou-Charente représentant le taux d'abtention prédit des élections municipales en 2008

Le code pour l'affiche des cartes se trouve ici.
Conclusion
Ce projet informatique nous a permis de trouver quelles sont les variables socioéconomiques les plus influentes mais également de réaliser des prédictions précises sur le taux d'abstention. Ce type de projet peut s'avérer très utile pour les politiques. En effet, en visualisant les communes ayant les taux d'abstention les plus importants, ils peuvent concentrer leurs futurs campagnes dans ces régions là, en allant voir des électeurs qui sont caractérisés par les variables socioéconomiques influents le plus le taux d'abstention. Les politiques peuvent alors faire campagne à un type d'électorat qu'ils pouvaient sous estimé.
Références
- Site web à partir duquel nous avons repris l'exemple d'analyse de ces données, Mr Alexandre VALLETTE
- Aide à la
cartographie sur R
- Récupération des données nécessaires à la cartographie
- Données détaillées localisées de l'INSEE
- La plateforme ouverte des données publiques françaises