Introduction
Twitter est un réseau social de microciblage qui permet à ses utilisateurs d'envoyer gratuitement de brefs messages (les tweets) limités à 140 caractères, et ponctués de hashtags (qui sont les mots-clés du tweet). Cette application est rapidement devenue populaire, si bien qu'elle est maintenant disponible en plus de 35 langues, et qu'on dénombre au 7 fevrier 2017, 320 millions d'utilisateurs actifs par mois, dont 14.1 millions en France, avec 500 millions de tweets par jour. Aujourd'hui, Twitter est une mine d'or concernant les sujets d'études, et ce, dans de nombreux domaines, comme la recherche en sociologie, linguistique, ou encore en sciences politiques. On dénombre de telles recherches pour, par exemple, prévenir un début d'épidémie de grippe, ou encore avertir les utilisateurs de catastrophes naturelles via un système d'alerte. En effet, dès qu'un utilisateur poste un tweet, il est transmis à tout son réseau d'abonnés, et permet donc de prévenir rapidement les habitants d'une zone à risques.
Les domaines d'applications sont donc vastes. Nous nous sommes intéressés, pour ce projet, à l'étude des sentiments sur Twitter, avec la répartition des sentiments au travers d'une recherche ciblée (un hashtag, un mot, ...), mais aussi aux sentiments associés à un utilisateur, en fonction des différents tweets qu'il poste.
Il est intéressant de noter qu'un procédé similaire a été utilisé par Cambridge Atlantica et Donald Trump pendant sa campagne, en récoltant les données des profils Facebook de 220 millions d'Américains. Ainsi, le jour du troisième débat entre Donald Trump et Hillary Clinton, 175 000 messages différents ont été envoyés sur Facebook, en étant adapté au niveau des quartiers, mais aussi au niveau des individus.
Notre objectif dans ce projet est de déterminer le profil émotionnel d'un individu à partir de son compte et d'étudier l'évolution de ce dernier au cours du temps. Tous les outils présentés dans ce rapport peuvent être transposés à l'analyse d'un corpus quelconque (pas seulement à l'analyse de tweets). Tout au long de ce rapport nous analyserons des tweets issus de personnalités différentes, ou de sujets très différents les uns des autres.
\newpage
Le nuage de mot: Un outil puissant de visualisation
Nous nous sommes tout d'abord intéressé à simuler un simple nuage de mot, lié à un utilisateur ou à un mot. Pour ce faire, il nous fallait récupérer un nombre n de tweets (par exemple 1000) sur un sujet ou un utilisateur précis. Une fois ces tweets récupérés, il fallait les « nettoyer », grâce à une fonction que nous avons créé (la fonction « finale »), qui permet de retirer les liens présents dans un tweet, les différents hashtags, ou même les mots récurrents de la langue française (ou anglaise, suivant ce que l'on choisit) comme les pronoms, puisque tous ces mots n'apportent aucune information pertinente.Une fois tous ces traitements effectués, il ne reste plus qu'à appliquer la fonction « wordcloud » pour obtenir le nuage de mot. Ce graphique fait apparaître les mots que nous retrouvons le plus dans les tweets récupérés. De plus, plus un mot est grand sur l'affichage, plus il apparait fréquemment.
Par exemple, et pour reprendre le cas de Donald Trump, nous avons construit un nuage de mot en prenant 1000 tweets de son compte Twitter, pour obtenir le résultat suivant :
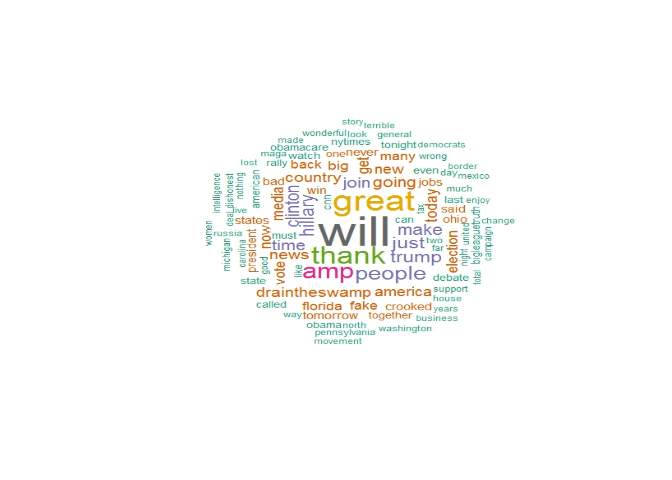
Nous pouvons donc voir, selon l'importance des mots, que plusieurs thèmes se dessinent, tels que des élément de sa campagne jusqu'à son élection, ou encore ce qu'en disent les médias.
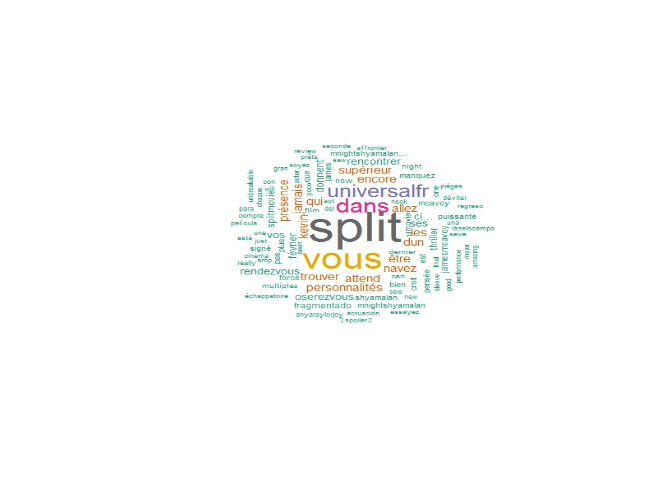
De même, en recherchant les tweets liés au film « split », qui vient de sortir aux Etats Unis, nous trouvons un nuage de mot correspondant à l'univers du film avec le nom du personnage, du réalisateur, ou même le thème du film, ainsi que quelques avis.
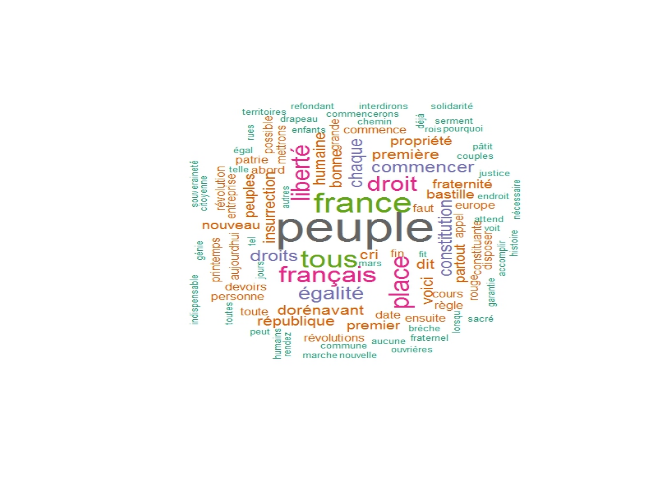
Un troisième exemple est une analyse sous forme de nuage de mots d'un discours de Jean-Luc Mélenchon, dans lequel il cite les valeurs des citoyens français, et semble aussi parler de son programme pour les présidentielles de 2017. De plus, il semble accorder une certaine importance au peuple français, puisqu'il fait partie des premiers mots lisibles sur le nuage, impliquant qu'il les a prononcé de nombreuses fois.
Le nuage de mot est donc un outil assez puissant pour trouver les idées importantes de tous types de documents, tels que des discours, des livres, ou même des tweets. Cependant, ces résultats ne nous servaient pas comme tels, c'est pourquoi nous avons complété cette approche en utilisant les sentiments.
\newpage
Modèle LDA pour la détection de sujets
Etant donné un corpus de documents (tweets) nous voulons déterminer quels sont les principaux sujets dans ce corpus. Pour ce faire nous avons utilisé un modèle probabiliste génératif de corpus, le Latente Dirichlet Allocation (LDA). L'idée est de considérer qu'un document est un mélange aléatoire de sujets et que chaque sujet est caractérisé par une distribution de mots qui lui est propre. Ainsi, selon ce modèle, générer un document se fait de la manière suivante : pour chaque document on tire une distribution de sujets, (selon une loi de Dirichlet) on tire ensuite un sujet puis un mot selon la distribution des mots dans les sujets, et ainsi de suite. Dans ce modèle, chaque mot est tiré indépendament des autres mots, ce modèle considère chaque document comme un "sac de mots". L'image suivante résume bien le modèle.
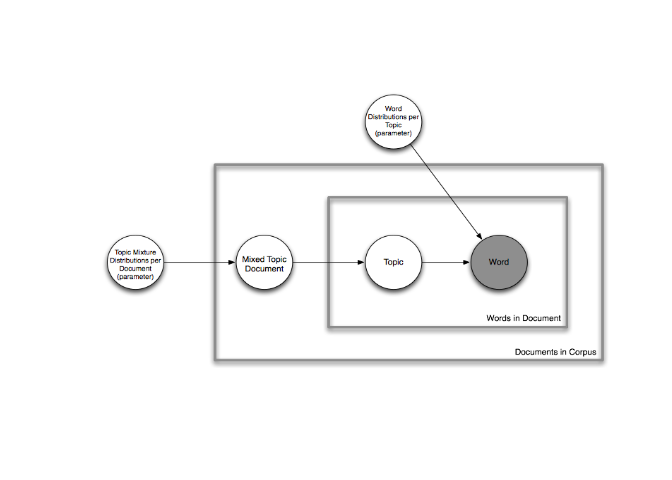
Dans ce modèle, on suppose le nombre de sujets inhérent à un discours
connu et celui-ci nous est dans la pratique a priori inconnu ! Alors,
comment estimer le nombre optimal de sujet dans un corpus de documents ?
Nous avons estimé le nombre optimal de sujets par la méthode de la
silhouette moyenne optimale. On définit la statistique de la silhouette
(Kaufman et Rousseeuw 1990) par
$s(i)= \frac{b_{i}-a_{i}}{max(a_{i},b_{i})}$ avec ai
la moyenne des distances entre l'élément xi et le reste
des éléments de sa classe et bi la moyenne des distances
entre xi et les observations du groupe le plus proche. On
dira qu'un élément xi est bien classé si s(i) est
grand. Le nombre optimal de clusters est alors l'entier k qui maximise
la moyenne des s(i). La silhouette est une valeur indiquant comment
un objet est similaire à son propre cluster comparativement aux autres
clusters.
Cette valeur évolue entre -1 et 1, et plus la valeur est élevée, plus
l'objet est similaire avec son cluster. Ainsi, si de nombreux objets ont
une silhouette élevée, alors la configuration des clusters est
appropriée. Dans l'estimation par silhouette, il est question de
métrique. Nous avons dans ce projet utilisé la distance de Manhattan.
Cette distance s'apparente au chemin parcouru entre deux points d'un
réseau en utilisant uniquement des déplacements verticaux et
horizontaux, et non diagonaux. On peut l'écrire de la façon suivante :
$d(X,Y) = \underset{1 \le i \le n}\sum{|x_{i}-y_{i}|}$ avec
X = (x1, ..., xn) et
Y = (y1, ..., yn). Autrement dit, la
distance associée à la norme 1.
Une fois le nombre optimal de sujets (ou classes) déterminé nous pouvons effectuer une LDA sur nos tweets. Voici le résultat sur le discours de la bastille de Jean luc Mélenchon. On affiche ensuite les dix termes les plus représentatifs de chaque sujet.

Il est possible de retrouver des termes identiques dans des sujets
différents. En effet, certains termes identiques peuvent être utilisés
dans des contextes très différents, ou pour raconter des choses très
différentes. C'est souvent le cas avec les discours des politiciens. On
retrouve ici bien l'idéologie de Jean Luc Mélenchon au travers des
différents sujets. On peut effectuer la même chose sur son profil
twitter afin de comparer le nombre de sujets trouvés sur son twitter et
le nombre de sujets trouvés au cours de son discours à la bastille.

On retrouve ici seulement deux sujets, qui sont d'ailleurs fortement
liés. finalement on remarque aux termes les plus représentatifs des
sujets de JL Mélenchon qu'il utilise principalement son twitter pour
décrire son actualité politique, remercier ses followers, anoncer des
déplacements, discours etc... Il est évident qu'il est important au
cours d'un discours de traiter du plus grand nombre de sujets possibles,
en ce sens on comprend très bien la nette différence entre le nombre de
sujets traité sur un réseau social (qui est ici utilisé comme un moyen
puissant de communication) et un discours.
On arrive à trouver le nombre optimal de sujet dans un corpus, cependant qu'en est il de l'évolution de ces sujets dans le temps ? Bien qu'il y ait plusieurs sujets chers à un individu, ils ne sont pas forcémment représentés dans les mêmes proportions. On peut très bien imaginer qu'en fonction de l'actualité, des sujets reviennent plus souvent que d'autres. Ca tombe très bien puisque les tweets des individus sont datés, on va maintenant regarder l'évolution de la répartition des sujets de jean Luc Mélenchon au cours de ces derniers jours.
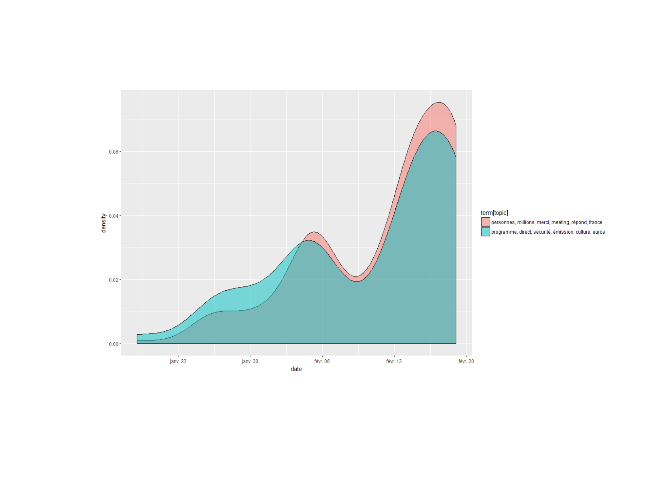
On remarque sur cet exemple qu'il y a une évolution conjointe des deux sujets de JLM, il utilise les deux "sujets" trouvés de manière proportionnelle. Il est quand même amusant de remarquer qu'il y a des pics d'activités lorsqu'il sort des vidéos sur son compte youtube ou qu'il fait des meetings.
Qu'en est-il des relations entre les différents sujets ? Reprenons l'exemple du discours de Mr Mélenchon. On affiche ici, encore par une modélisation LDA les corrélations qu'il y a entre les différents sujets de son discours.
Il apparait clairement qu'il y a une poignée de sujets liés entre eux, on vérifie ici que certains sujets possédant pourtant des termes en commumn ne sont pas liés. Cela traduit le fait qu'un même terme peut être utilisé dans des contextes très différents et vouloir dire des choses différentes.

On voit ici très bien les relations entre les sujets trouvés un peu
plus tôt ! Qu'en est il des tweets de Jean-Luc Mélenchon ? Nous avons vu
que les deux sujets évoluaient conjointement et de manière
proportionnelle, cela veut-il dire que les deux sujets sont liés ? Voici
le graphe des relations entre les deux sujets:

\newpage
Détection des émotions:
Le modèle d'analyse de sentiments utilisé est basé sur un lexique dont le principe est la détection exacte avec des éléments d'un dictionnaire. A chaque élément du dictionnaire on associe une fonction de score qui dépend non seulement du terme employé, mais aussi du contexte. On obtient ainsi un score pour chaque sentiment (voir tableau ci dessous), un vote majoritaire nous permet de déterminer le sentiment dominant ainsi que la polarité (sentiment positif ou négatif).De plus, le score obtenu par cette émotion détermine "l'intensité" du sentiment. Il y a 8 sentiments analysés par notre modèle: la peur, l'anticipation, la colère, la joie, la confiance, le dégoût, le bonheur et la tristesse. Nous avons rajouté un sentiment, le sentiment neutre. Il dépend des scores obtenus par les autres sentiments. On considère qu'un invididu est dans un état émotionnel neutre lorsque sa fonction de score est identiquement nulle. De plus, nous considérons qu'il n'y a pas d'intensité du sentiment neutre, l'émotion neutre peut être vue comme une indicatrice de l'absence de sentiments.

Il est maintenant possible de déterminer le profil émotionnel d'un
individu en fonction de ses tweets, i.e. déterminer la composition de
son twitter en terme de sentiments. C'est ici ce que nous faisons avec
le profil de Donald Trump.
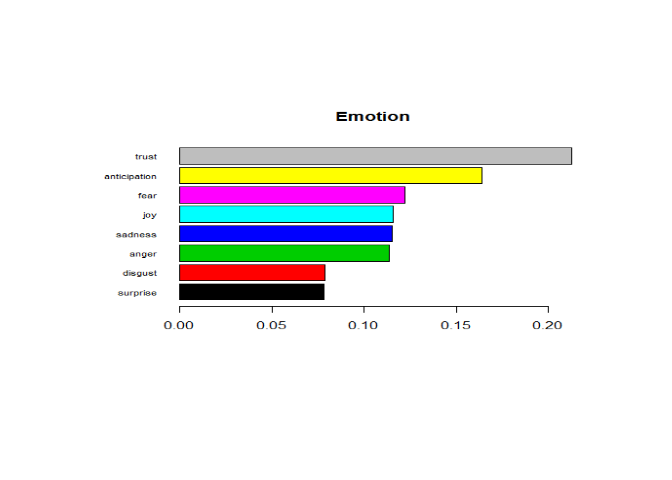
Ici on retrouve essentiellement deux émotions qui caractérisent le
twitter du nouveau président américain, la confiance et l'anticipation.
Dans la suite, nous ferons le parallèle entre les émotions analysées sur
son twitter et les émotions véhiculées dans son discours d'investiture.
Maintenant que nous sommes capables d'associer un terme (dans un certain
contexte) avec un sentiment, on peut réaliser des nuages où chaque mot
est associé à une émotion. Voici quelques exemples:
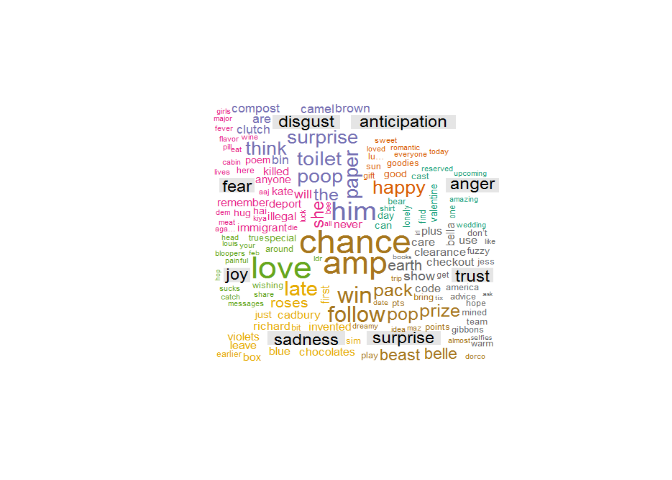
Ici nous avons fait une recherche sur le hashtag associé à la Saint
Valentin, voici le nuage de mots obtenu :
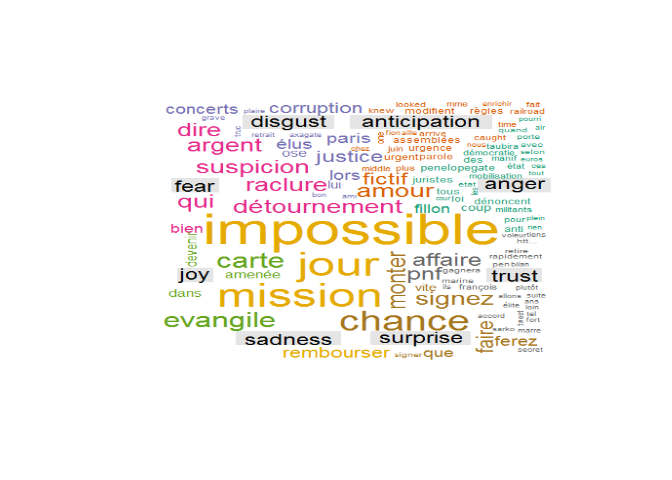
En ce début d'année 2017, la vie politique française est animée par différentes "affaires",dont l'affaire Fillon. Nous affichons ici le nuage de mots associés aux tweets possédant le hashtag #penelopegate:
Les nuages de mots qui sont déjà un outil de visualisation très puissant prennent une autre envergure. On a une lecture bien plus fine du nuage de mots. On arrive tout de suite à catégoriser et avoir une idée générale du propos d'un individu, ou d'un ensemble d'individus sur un sujet.
Comme il est possible de dresser le profil émotionnel d'un individu, concentrons nous maintenant sur l'évolution de ces émotions au cours du temps. Pour cela on récupère les tweets de Francois Fillon sur son compte twitter officiel, on fait ensuite une analyse de sentiments, puis on affiche la distribution des sentiments sur les 500 derniers tweets de François Fillon.
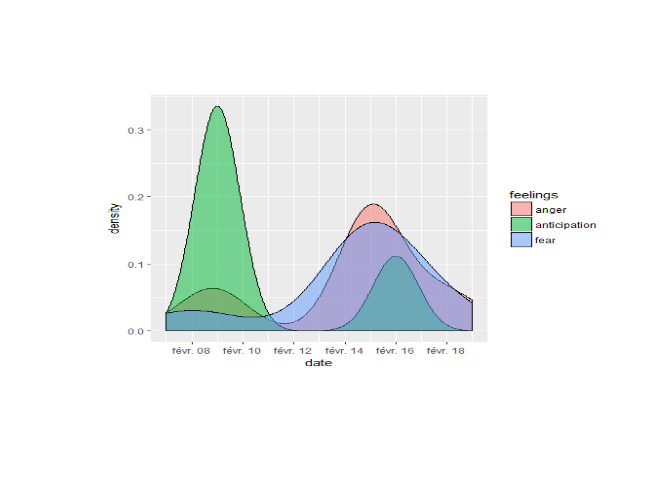
On note plusieurs choses, entre le 8 février et le 18 février on
assiste à une très forte augmentation de la colère ainsi que de la peur
et une diminution flagrante de l'anticipation. Tout ceci est fortement
compréhensible étant donné les circonstances.
On peut maintenant comparer les émotions trouvées sur le compte de Francois Fillon avec la répartition des émotions des tweets discutant de François Fillon. On récupère ici les 1000 derniers tweets:
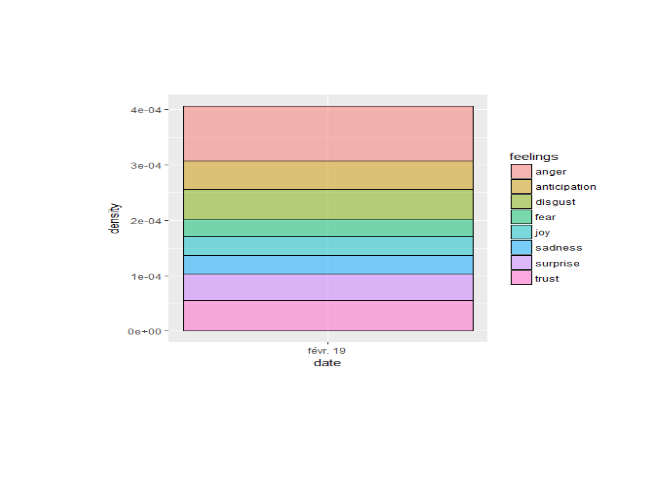
On a ici seulement des tweets sur la journée du 19 février car il y a
une très grande quantité de tweets postés tous les jours sur François
fillon. On distingue essentiellement de la colère et du dégoût, il y a
aussi une partie non négligeable de tweets traduisant de la confiance,
on peut sans trop se mouiller attribuer ces tweets aux millitants de
François Fillon.
Comment savoir si un film d'horreur fait vraiment peur ? Nous allons essayer de répondre à cette question en ne regardant que les tweets discutant d'un film d'horreur. Pour cela nous récupérons des tweets sur un film sorti très récemment au cinéma "A cure for life". Nous récupérons 500 tweets sur le hashtag du film #acureforlife et nous procédons à une analyse des sentiments "générés par ce film".
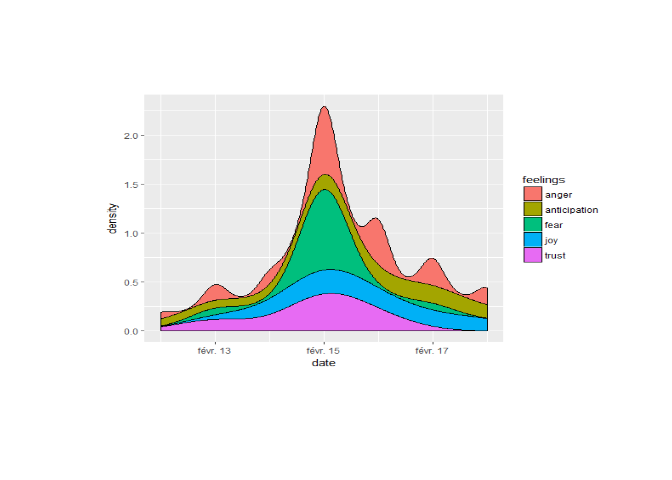
La première chose à remarquer est l'augmentation considérable du nombre
de tweets parlant du film le 15 février soit le jour de sa sortie. La
très grande partie des tweets sont associés à la peur, le film est donc
bien un film d'horreur, qui à en voir les émotions qu'il suscite, est
plutôt efficace. La confiance et la colère sont deux émotions très
présentes, pour ce qui est de la confiance on étudie une rapide
diminution jusqu'a sa disparition peu de temps après la sortie du film.
Cet outil est assez intéressant pour étudier les émotions générées par
un film, vérifier si la réaction du public est bien celle attendue et
suivre la popularité du film dans le temps.
\newpage
D'où Twittez-vous ?
L'objectif dans cette partie est de localiser des utilisateurs de twitter. Dans un premier temps on va géolocaliser les "followers" d'un compte donné. Pour ce faire on va utiliser la fonction twitterMap développée par le biostatisticien Jeff Leek. On affiche ici les followers du président Donald Trump:
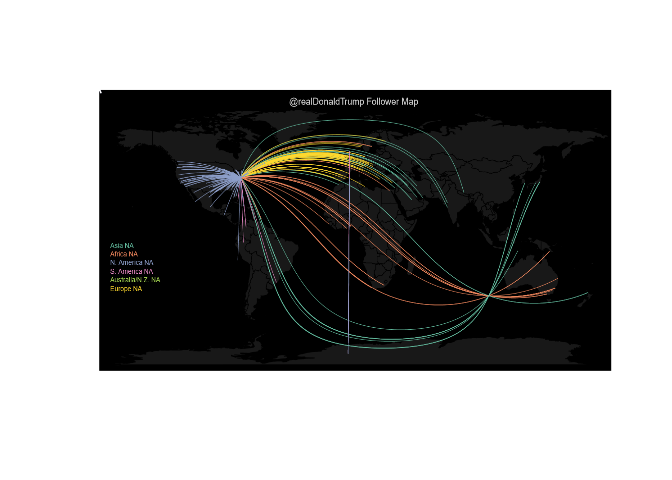
Outre la beauté du graphique, on note la "popularité" de Donald Trump.
Il est suivi dans le monde entier, avec une moindre popularié en
Amérique du Sud et sur le continent Africain. Les Etats-Unis sont une
puissance économique et culturelle indéniable, il est compréhensible que
son chef soit suivi dans le monde entier.
Dans un second temps, nous voulons afficher les utilisateurs de Twitter qui "tweetent" sur un sujet donné. Pour cela, nous nous sommes heurtés à un problème de taille : moins de 1% des utilisateurs activent la géolocalisation sur Twitter. En effet, si l'utilisateur n'active pas manuellement la localisation, il n'est pas géolocalisé (ce qui est plutôt rassurant !). De plus, on ne peut pas télécharger plus de 15000 tweets toutes les 15 min. Même en téléchargeant 15000 tweets en un seul coup, il n'est pas rare de n'avoir aucun tweet géolocalisé ! Pour contourner ce problème nous avons utilisé un petit tour de magie. A chaque tweet chargé, nous récupérons le profil de l'individu qui poste le tweet, puis nous géolocalisons son profil à partir des informations de ce dernier. Evidemment, cette méthode induit un certain biais, il n'est pas evident que la localisation indiquée par un utilisateur de Twitter est réellement l'endroit où il vit. Cependant, avec ce procédé on arrive a géolocaliser environ 60% des utilisateurs. Voici la géolocalisation de 300 individus qui tweetent sur le hashtag #penelopegate sur l'affaire Fillon.
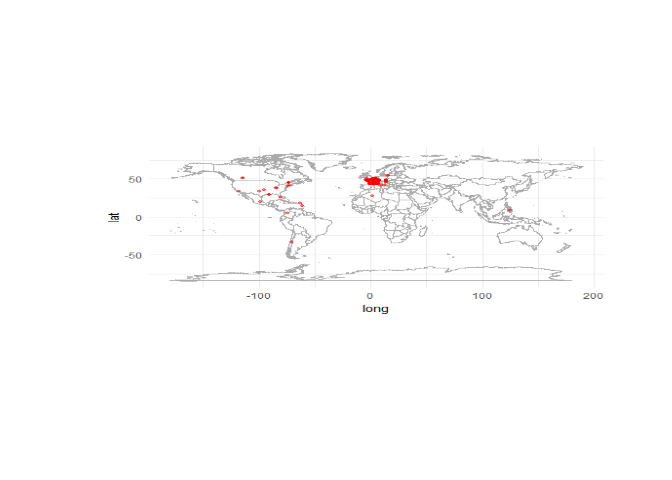
Il est évident que cette affaire est surtout commentée en France, elle
ne préoccupe en rien les individus des autres pays, c'est vérifiable sur
la carte ci-dessus.
Maintenant que nous sommes capables de géolocaliser les individus à partir d'un sujet ou d'un compte qu'ils suivent, nous allons étudier les sentiments associés à chaque tweet posté, nous faisons ensuite un vote majoritaire pour déterminer le sentiment dominant dans le tweet en question puis nous géolocalisons la personne qui a posté le tweet. Finalement nous pouvons afficher une sorte de carte des émotions sur un sujet donné. Voici la carte des émotions toujours sur le hashtag #penelopegate.
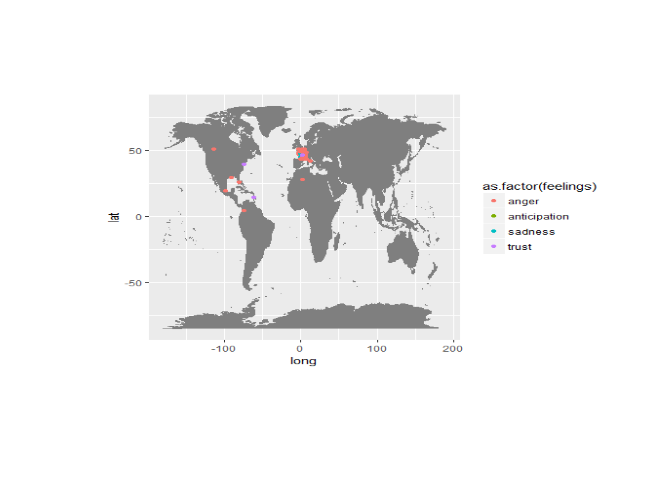
Sans grande surprise, on valide ici tout ce qui a été énoncé plus tôt.
L'affaire Fillon est une affaire qui est tweetée presque exclusivement
en france, de plus on retrouve bien la colère comme émotion très
dominante !
\newpage
Application Shiny.
Au cours de ce projet nous avons développé une application shiny pour recenser tous ces résultats. Elle permet donc, en rentrant un hashtag ou un compte twitter, de récupérer le nuage de mot associé ainsi que celui lié au sentiments, la répartition des sentiments dans les tweets récupérés, l'évolution des sujets et des sentiments au cours du temps, et la polarité. Il est aussi possible d'affiner la recherche en précisant la langue des tweets que l'on souhaite récupérer, leur nombre, et de préciser une date, ou un intervalle de temps. Il est toutefois important de signaler que les fonctions du package twitteR ne permettent pas de récupérer des tweets vieux d'il y a plus de 7 jours (à moins de ne travailler que sur les comptes des utilisateurs). Enfin, il est possible de directement télécharger les graphiques obtenus grâce aux différents boutons "download" présents sur l'application.
Il est aussi possible d'effectuer une analyse de texte, avec cette application, bien que cette partie soit moins développée. Il suffit d'importer un document (un discours, un script, ou même un livre) au format .txt et de spécifier sa langue (anglais ou français), pour que l'application retourne les deux nuages de mots ainsi que la répartition des sentiments dans ce texte. L'évolution temporelle étant dans ce cas plus difficile à définir, puisqu'elle dépend en grande partie du document importé, les autres graphiques ne sont pas réalisés.
L'application est disponible ici : https://ekmanalyst.shinyapps.io/twitter_shiny2/
\newpage
Bibliographie
Turenne Nicolas, Analyse de données textuelles sous r, iste editions, 2016
Twitter sentiment analysis with R, Disponible sur https://www.r-bloggers.com/twitter-sentiment-analysis-with-r/
Introduction to Latent Dirichlet Allocation, Disponible sur http://blog.echen.me/2011/08/22/introduction-to-latent-dirichlet-allocation/
Deux méthodes d'apprentissage non supervisé : synthèse sur la méthode des centres mobiles et présentation des courbes principales, Disponible sur http://www.proba.jussieu.fr/dw/lib/exe/fetch.php?media=users:fischer:clusteringcourbesprincipales.pdf
An R function to map your Twitter Followers, Disponible sur http://simplystatistics.org/2011/12/21/an-r-function-to-map-your-twitter-followers/
Package 'syuzhet', Disponible sur https://cran.r-project.org/web/packages/syuzhet/syuzhet.pdf