OpenData Bordeaux
Sommaire
Représentation graphique de Bordeaux et ses
équipements publics
Parcs / jardins
Ecoles
Points
lumineux
Application shiny
Peux-t-on predire les revenus des quartiers avec
les équipements publics ?
Revenus
Corrélation
des variables
Régression linéaire
Random Forest
Introduction
Comme la plupart des grandes villes francaises, la ville de Bordeaux met à disposition, depuis 2012, de données publiques. L'ouverture de ces données a pour objectif d'améliorer la transparence des actions publiques, mais surtout de stimuler l'innovation et le développement de nouveaux services, par le biais d'applications ou de sites web par exemple.
La ville de Bordeaux met ainsi a disposition 150 jeux de données, ainsi qu'une API, c'est à dire un outil permettant de visualiser les données du portail. Il est possible de télécharger ces données à l'adresse : http://opendata.bordeaux.fr/. La ville propose également un portail mutualisé avec l'ensemble de la métropole : https://data.bordeaux-metropole.fr/.
Nous allons donc exploiter ces données en s'intéressant aux equipements publics de la ville de Bordeaux. Nous allons dans un premier temps représenter certains équipements qui nous semblent pertinents pour en étudier la répartition. Puis nous essaierons d'établir une relation entre la répartition de ces équipements, et les revenus par quartier.
Description des données
Nous décidons donc de nous intéresser aux équipements publics sur la commune de Bordeaux. Pour étudier la répartition de ces équipements sur l'ensemble de la ville, nous avons décidé de diviser la ville selon ses Iris (Ilots Regroupés pour l'Information Statistique). Ce découpage a été mis en place par l'Insee et vise à découper le territoire en mailles d'environ 2000 habitants.
Pour pouvoir représenter les équipements sous forme de carte, nous avons besoin, dans un premier temps, de dessiner le fond de carte, c'est à dire Bordeaux découpé en Iris. Pour cela, nous nous sommes appuyés sur un tutoriel d'introduction à la cartographie, sous R : https://rstudio-pubs-static.s3.amazonaws.com/47698_6effe42ff227451ab364b393d0bcf495.html. Nous utilisons les packages sp et rgdal pour importer le fond de carte au format SHP, et les packages RColorBrewer et classInt pour gérer les palettes de couleur utilisées. Enfin, les packages ggplot2, ggmap, et maptools nous permettrons de faire le rendu de ces cartes. On importe donc les données shp des Iris grâce à la fonctionreadOGR, puis on ne garde que les Iris associés à la ville de Bordeaux.
# Load fichier SPS des Iris de toute la France
pathToShp <- "Lartigau-Ges/iris/CONTOURS-IRIS/1_DONNEES_LIVRAISON_2015/CONTOURS-IRIS_2-1_SHP_LAMB93_FE-2015"
iris <- readOGR(dsn = pathToShp, layer="CONTOURS-IRIS", stringsAsFactors=FALSE)
# Filtrage des données pour ne garder que Bordeaux
bdx <- iris[iris@data$INSEE_COM=="33063",]
On obtient alors un objet de classe SpatailPolygonsDataFrame, qui contient en fait plusieurs slots :
## Formal class 'SpatialPolygonsDataFrame' [package "sp"] with 5 slots
## ..@ data :'data.frame': 88 obs. of 6 variables:
## ..@ polygons :List of 88
## ..@ plotOrder : int [1:88] 11 56 32 67 9 19 47 52 25 48 ...
## ..@ bbox : num [1:2, 1:2] 412638 6418798 420950 6430452
## .. ..- attr(*, "dimnames")=List of 2
## ..@ proj4string:Formal class 'CRS' [package "sp"] with 1 slot
On peut alors représenter les Iris de Bordeaux :
plot(bdx)
Nous pouvons alors importer les données des équipements. Nous avons
d'abord aggrégé l'ensemble des équipements dans un data frame comprenant
le nom de l'equipement, ses coordonnées (longitude, latitude), et le
type de cet équipement (exemple : aire de jeu). Nous avons également
importé un data frame comprenant, entre autres, le nombre d'habitants
par Iris, ainsi que le revenu médian par Iris.
Nous voulons alors créer un data frame final, comprenant le nombre de chacun de nos équipements par Iris selon leur type. Cependant, les projections selon lesquelles sont déterminées les coordonnées des équipements et des Iris ne sont pas les mêmes. Les équipements sont sous projection Transversale universelle de Mercator (UTF) alors ques les Iris sont sous projection de Lambert. Nous convertissons donc les coordonnées des équipements pour qu'elles soient compatibles avec les Iris.
On obtient alors un data frame final à partir duquel nous allons étudier la répartition des équipements. Le data frame est de la forme suivante :
head(df_final)
## INSEE_COM NOM_COM IRIS CODE_IRIS NOM_IRIS
## 1 33063 Bordeaux 0703 330630703 Villa Primerose Parc Bor.-Cauderan 3
## 2 33063 Bordeaux 0804 330630804 Lestonat-Monsejour 4
## 3 33063 Bordeaux 1102 330631102 Capucins-Victoire 2
## 4 33063 Bordeaux 0310 330630310 Chartrons-Grand-Parc 10
## 5 33063 Bordeaux 0603 330630603 Saint-Seurin-Fondaudege 3
## 6 33063 Bordeaux 0303 330630303 Chartrons-Grand-Parc 3
## TYP_IRIS Aire jeux Defibrillateur Parc Jardin Ecole Point lumineux
## 1 H 0 0 0 3 175
## 2 H 1 1 1 2 189
## 3 H 1 1 1 2 226
## 4 H 0 0 0 2 215
## 5 H 1 0 1 0 162
## 6 H 2 0 1 0 236
## Borne controles acces Cendrier Distributeur proprete
## 1 0 0 0
## 2 1 2 1
## 3 4 3 3
## 4 0 1 0
## 5 0 1 2
## 6 0 0 2
## Panneaux d'affichage Poubelle WC Stationnement deux roues
## 1 1 10 0 2
## 2 0 14 1 4
## 3 0 37 2 19
## 4 0 12 0 1
## 5 1 9 0 3
## 6 2 8 0 7
## DEC_NBMENFISC12 DEC_NBPERSMENFISC12 DEC_NBUC12 DEC_MED12 superficie
## 1 1092 2451.0 1697.8 32010 310006.0
## 2 1081 2218.5 1585.8 26214 347808.5
## 3 1014 1538.5 1248.6 15112 104783.6
## 4 1137 2174.5 1590.4 26250 188773.3
## 5 1134 2096.5 1565.8 26620 288578.3
## 6 1712 3266.0 2385.1 17882 368053.9
Représentation graphique de Bordeaux et ses équipements publics
Nous allons maintenant étudier les équipements de Bordeaux. Nous allons représenter la répartition de ceux qui nous semblent pertinents pas Iris.
Parcs / jardins
On représente d'abord le nombre de parcs et jardins dans chaque Iris.
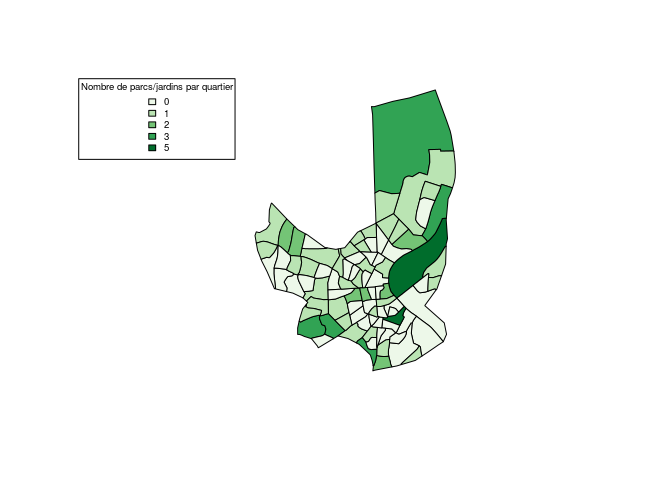
De nombreux Iris ne comprennent pas de parc ou de jardin. Le nombre
d'espaces verts est en général lié à la taille de l'Iris
Ecoles
On observe le nombre d'écoles pas Iris.
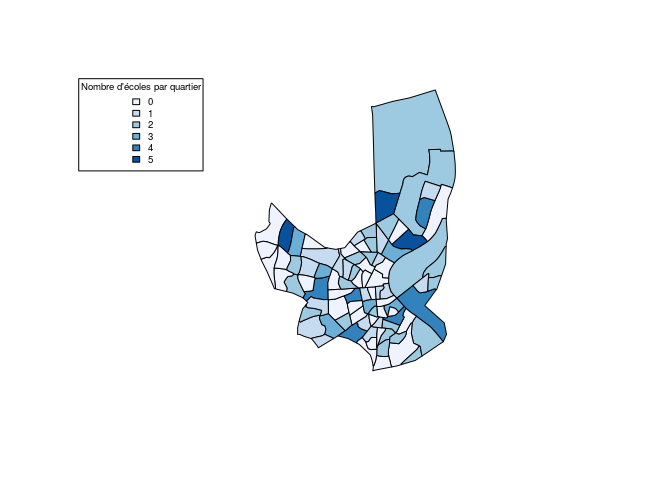
On souhaite voir si la répartition des écoles est proportionnelle au
nombre d'habitants par Iris (on ne possède pas les données concernant le
nombre d'enfants scolarisés par Iris)
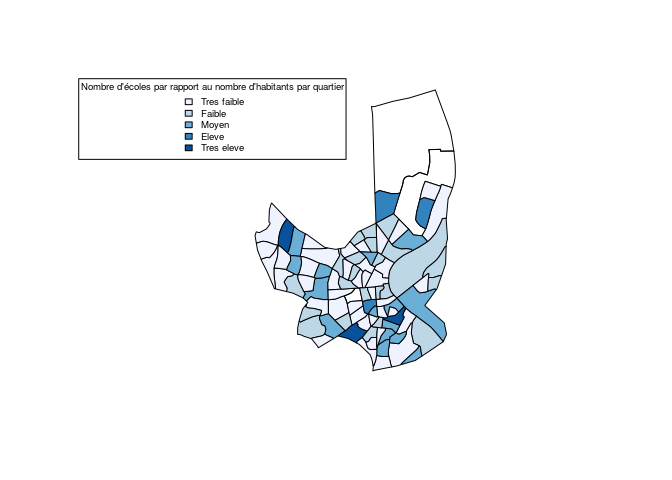
On observe que le nombre d'écoles par rapport à la population à
l'intérieur de l'Iris est relativement homogène, même si certains Iris
ont un nombre d'écoles par habitant plus élevé.
Points lumineux
On s'intéresse ici au nombre de points lumineux dans chaque iris, c'est à dire le nombre de sources de lumières présentes sur cet iris.
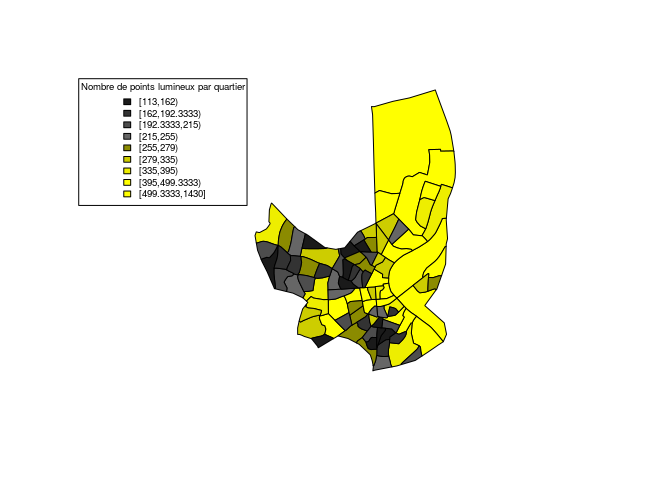
On constate logiquement que les quartiers les plus grands en superficie
comprennent de nombreux points lumineux. On décide donc de s'intéresser
à une nouvelle variable, que nous appèlerons luminosité, qui correspond
en fait au rapport entre le nombre de points lumineux et la superficie
de l'iris. Cette variable correspond en fait à la concentration
lumineuse des iris.
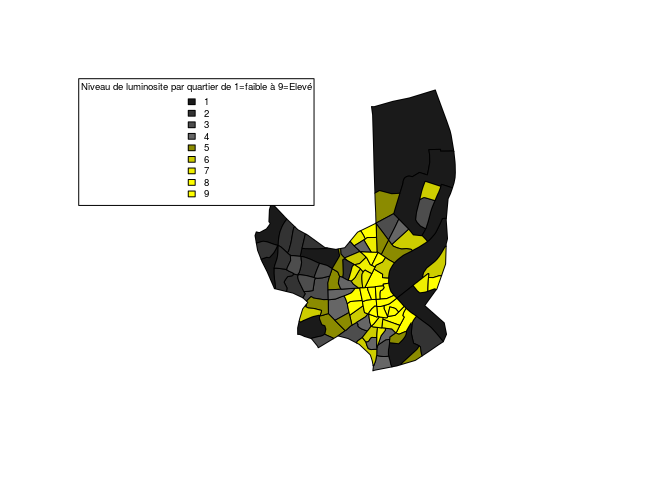
Avec cette nouvelle variable, on peut observer que le centre ville de
bordeaux est la partie la plus lumineuse de la ville, alors que les iris
en périphérie sont moins éclairés.
Application shiny
Nous avons créé une application shiny permettant de représenter la répartition des équipements selon les Iris, mais aussi de localiser ces équipements dans les Iris. Cette application est disponible à l'adresse suivante : https://tlartigau.shinyapps.io/OpenDataBordeaux/.
Peux-t-on predire les revenus des quartiers avec les équipements publics ?
On veut maintenant établir s'il existe une relation entre la répartition des équipements publics et le revenu médian par Iris. Autrement dit, est ce que les personnes ayant des revenus plus élevés habitent dans des quartiers mieux équipés ?
Revenus
Notre jeu de données de revenus contient des données concernant les revenus par Iris à Bordeaux en 2012. Nous choisissons de garder le nombre d'habitants dans les ménages fiscaux par Iris et le revenu moyen par Iris. On représente les iris en fonction de leur revenu médian.
Note : nos données sur les revenus datent de 2012 et les Iris ont été modifiés depuis cette date. Il nous manque donc les données de revenus pour 3 Iris qui apparaissent en gris sur la carte.
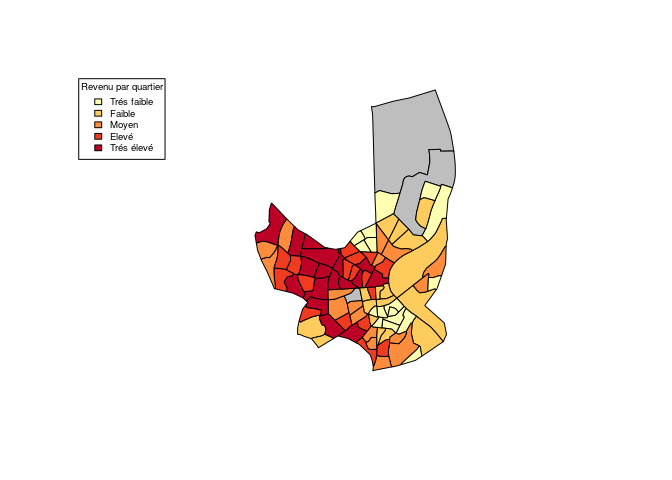
On peut observer que les quartiers ouest sont les quartiers de Bordeaux
dans lesquels le revenu médian est le plus élevé.
Corrélation des variables
On étudie la corrélation entre nos variables, c'est à dire entre le nombre d'équipements selon leur type, la superficie, le nombre d'habitants et les variables de revenus.
On trace d'abord le corrélogramme pour les données brutes.
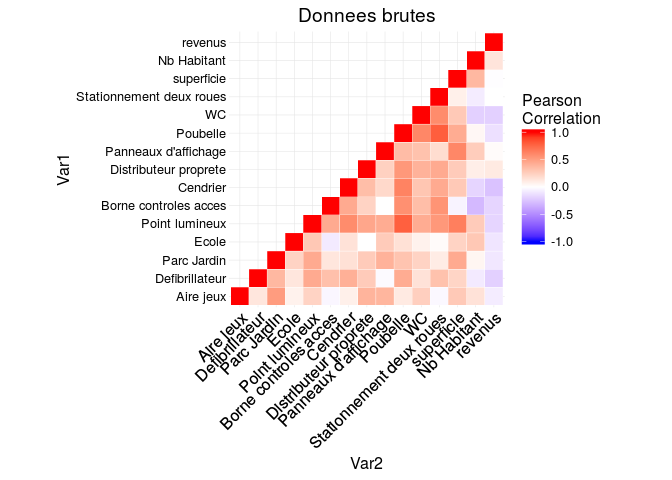
A partir des données brutes, il est difficile de dégager des
corrélations entre les différentes variables. En effet, le nombre
d'équipement est corrélé entre les différents types d'équipement : si le
nombre de points lumineux est élevé, le nombre de poubelles le sera
également. Cela est dû au fait que le nombre d'équipements est fortement
lié à la superficie de l'Iris.
Il est donc logique d'étudier le nombre d'équipements par Iris par rapport à la superficie de l'Iris. On trace le corrélogramme des équipements par rapport à la superficie.
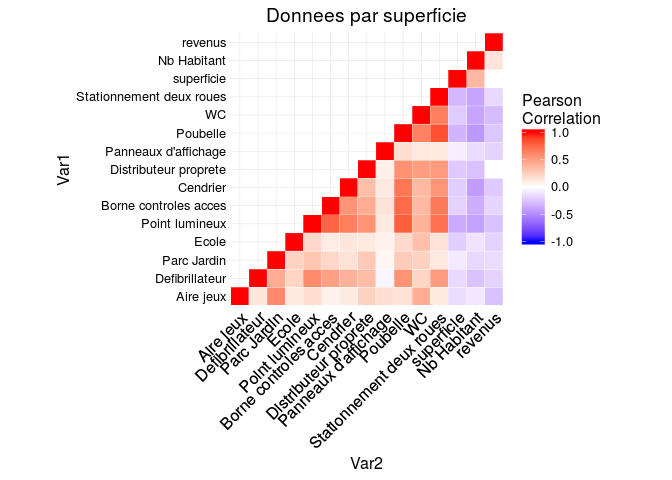
Le corrélogramme ne permet toujours pas de dégager de corrélations
pertinentes.
On essaye maintenant d'établir des corrélations sur les données divisées par le nombre d'habitants.
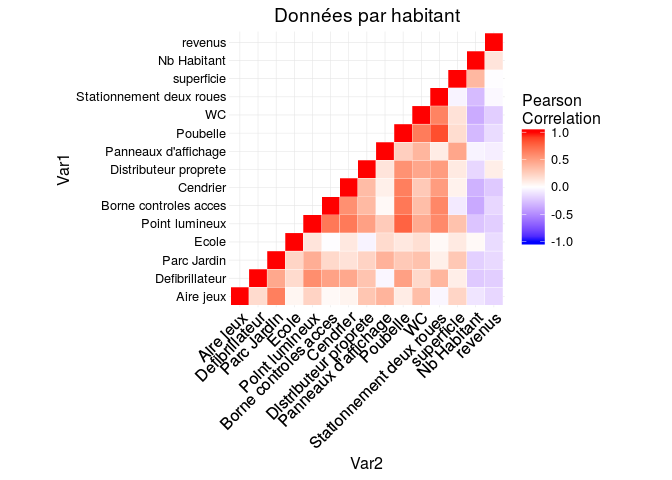
Aucune corrélation forte n'apparait.
Modélisation
Nous allons maintenant essayer d'établir un modèle pour prédire le revenu médian d'un Iris en fonction du nombre d'équipements. Puisque l'étude des corrélations ne nous a pas permis de dégager de variables plus importantes, nous décidons de baser ce modèle sur l'ensemble de nos équipements. Nous utiliserons les données du nombre d'équipements par rapport à la superficie de l'Iris dans nos modèles. De plus, nous enlevons les 3 iris pours lesquels nous ne possédons pas les revenus.
Régression linéaire
Nous commencons par établir un modèle par une simple régression linéaire.
Pour prédire nos données, nous utilisons la validation croisée k-folds pour k=10 folds. On divise en fait notre échantillon en 10 sous-échantillons, et on prédit chacun de ces sous-échantillons en fonction des 9 autres. On répète cette validation croisée 20 fois en modifiant les sous-échantillons à chaque fois. On obtient ainsi 20 prédictions pour chacune des valeurs à prédire, et on sélectionne la moyenne de ces prédictions.
B = 20
err.lm = rep(NA,B)
pred = matrix(NA,nrow=n,ncol=B)
for (b in 1:B)
{
n_folds<-10
folds_i<-sample(rep(1:n_folds,length.out= n))
for (i in 1:n_folds)
{
tr = which(folds_i==i)
datatrain <- data[-tr,]
Xtrain<-data[-tr,1:12]
Ytrain<-data[-tr,13]
Xtest<-data[tr,1:12]
reg = lm(revenus~.,data=datatrain)
pred[tr,b] = predict(reg,Xtest)
}
err.lm[b] = sum(abs(pred[,b] - data[,13]))/n
}
pred_mean.lm <- rowMeans(pred)
# On rajoute les NA
for (i in 1:length(id.na)){
pred_mean.lm <- append(pred_mean.lm,NA,id.na[i]-1)
}
Le vecteur err.lm contient les erreurs obtenues pour les 20 fois où on a effectué les prédictions. L'erreur moyenne obtenue est de :
mean(err.lm)
## [1] 4987.063
On dessine les cartes des revenus medians réels et des prédictions pour comparer les résultats obtenus.
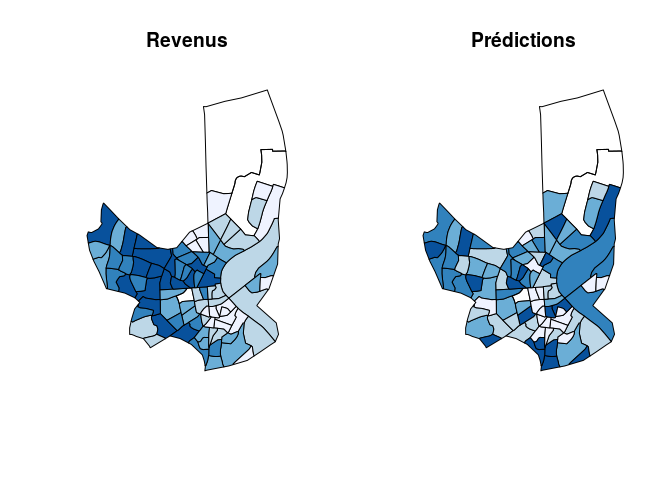
On peut remarquer que les prédictions obtenues via la régression
linéaire sont plutot mauvaises. On trace tout de même la carte des
erreurs de prédiction.
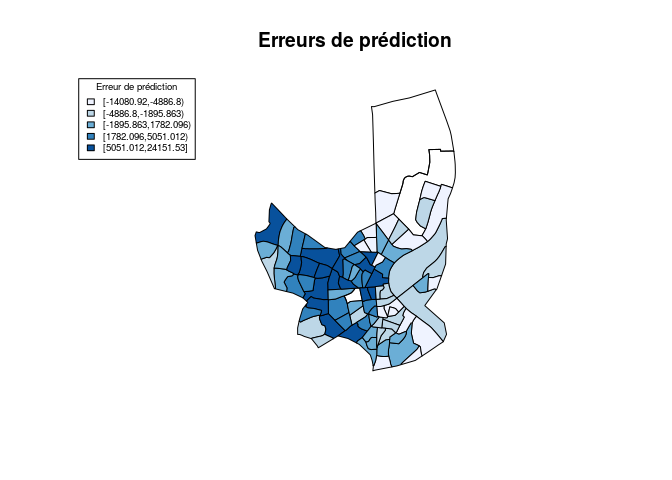
On observe alors que les erreurs les plus grandes sont commises sur les
Iris à l'ouest de Bordeaux, c'est à dire les quartiers ou le revenu
médian est le plus élevé.
Random Forest
On essaye donc de prédire les revenus médians avec une autre méthode : les forets aléatoires. Nous avons d'abord du estimer le nombre d'arbres et le nombre de variables à retenir pour notre foret aléatoire.
# Nombre d'arbres
nbarbs <- c(50, 100, 200, 300, 400, 500, 600, 750, 1000)
oobs <- rep(NA, length(nbarbs))
B <- 50
nbarbre <- rep(NA,B)
for(i in 1:B){
tr <- sample(1:n,round(80/100*n))
datatrain <- data[tr,]
Xtrain <- data[tr,1:12]
Ytrain <- data[tr,13]
Xtest <- data[-tr,1:12]
Ytest <- data[-tr,13]
for (nba in seq_along(nbarbs)) {
rf <- randomForest(revenus~.,data=datatrain, na.action = na.omit)
oobs[nba] <- rf$mse[nbarbs[nba]]
}
nbarbre[i] <- nbarbs[which.min(oobs)]
}
nbarbopt <- mean(nbarbre)
# Mtry
nbvars <- 1:12
oobs_mtry <- rep(NA, length(nbvars))
nbvar <- rep(NA,B)
for(i in 1:B){
tr <- sample(1:n,round(80/100*n))
datatrain <- data[tr,]
Xtrain <- data[tr,1:12]
Ytrain <- data[tr,13]
Xtest <- data[-tr,1:12]
Ytest <- data[-tr,13]
for (nbv in seq_along(nbvars)) {
rf <- randomForest(revenus~ ., data=datatrain, na.action = na.omit, ntree = nbarbopt,
mtry = nbv)
oobs_mtry[nbv] <- rf$mse[nbarbopt]
}
nbvar[i] <- nbvars[which.min(oobs_mtry)]
}
nbvaropt <- round(mean(nbvar))
nbarbopt
## [1] 285
nbvaropt
## [1] 3
Cependant les paramètres obtenus sont instables et varient beaucoup. Les résultats obtenus semblent, en moyenne, se rapprocher des paramètres par défaut de la fonction randomForest, qui sont n=500 arbres et le nombre de variables est mtry=p/3 (p étant le nombre de variables total).
De meme que pour la régression linéaire, on utilise la validation croisée k-folds que l'on répète 20 fois pour obtenir nos prédictions.
On obtient alors l'erreur moyenne suivante :
mean(err.rf)
## [1] 2168.933
L'erreur obtenue est bien plus faible que celle obtene avec la régression linéaire. On représente la carte des prédictions.
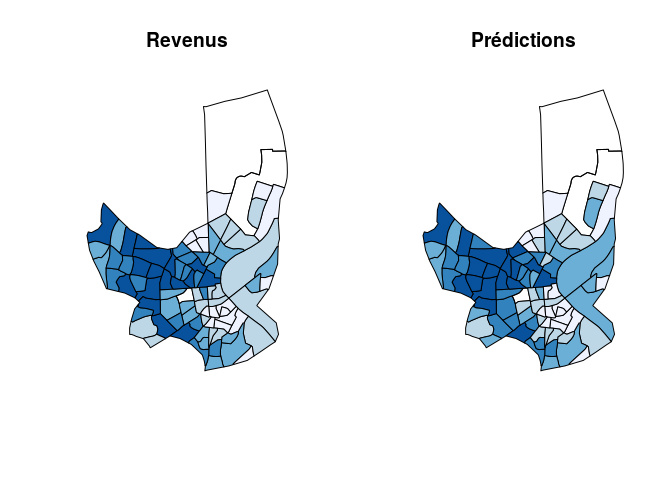
Ici, les prédictions obtenues semblent bien meilleures. En effet, la
répartition des prédictions est similaire à celle des revenus réels.
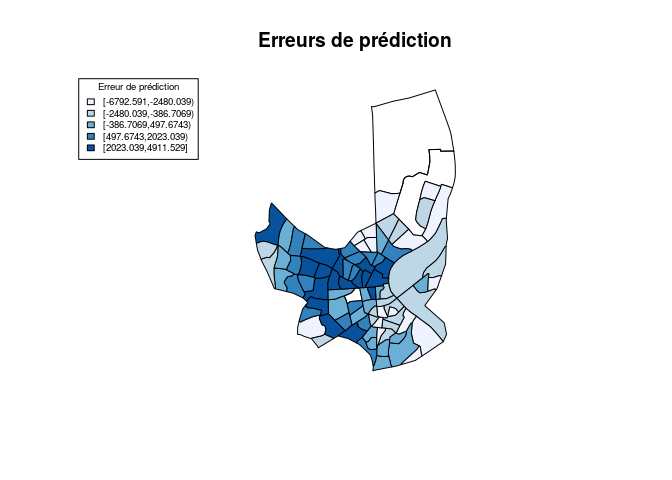
Les erreurs de prédiction sont une nouvelle fois plus élevées pour les
Iris ou les revenus sont les plus élevés.
Conclusion
Les donnée mise à disposition par la ville de Bordeaux permettent de situer de nombreux équipements publics. Nous avons ainsi pu représenter la répartition de ces équipements dans la ville. En revanche, il nous a été difficile de dégager des équipements ayant une corrélation avec le revenu médian par Iris. Nous avons tout de meme pu estimer le revenu médian de manière relativement juste en utilisant les random forest.