
Projet Open Data
Étude de l'évolution du sentiment public concernant la crise sanitaire du COVID-19 par analyse sentimentale de Twitter
Wael Ben Hadj Yahia, Dorian Hervé
M2 CMI ISI, 2020-2021
Introduction¶
Twitter est un réseau social de microblogage créé en 2006 qui permet de poster de courts messages appelés tweets. Les tweets ne peuvent dépasser 240 caractères. Twitter est, depuis un certain nombre d'années, considéré comme un outil permettant de suivre l'actualité.
L'accès à Twitter nécessite la création d'un compte. L'utilisateur dispose alors d'un fil d'actualités qui présente :
- les tweets publiés par les comptes auxquels il est abonné
- les tweets relayés ou commentés par ces mêmes comptes
Twitter compte plus de 300 millions d'utilisateurs mensuels actifs à travers la planète. Ce réseau social est donc une excellente source de données continue. En effet, 6000 tweets sont publiés chaque seconde, soit près de 200 milliards par an.
L'étude de ces données s'avère donc pertinente dans de nombreux domaines, comme la sociologie par exemple.
Objectif¶
L'objectif de ce travail est d'étudier l'évolution du sentiment public vis à vis de la crise sanitaire du Covid-19. Pour ce faire, nous allons procéder par une analyse sentimentale de tweets autour de ce sujet.
Données¶
Notre jeu de données principal est tiré de https://www.openicpsr.org/ et est téléchargeable ici. Celui-ci est à l'origine d'une étude réalisée par des chercheurs de Singapour au sujet du covid [1]. Il pèse 9 Go et a la structure suivante :
On a donc, pour chacun des 75 millions de tweets : son identifiant, le sujet de discussion auquel il appartient, les intensités des émotions considérées, la catégorie du sentiment, l'émotion relevée (colère, peur, tristesse, pas d'émotion spécifique, et joie), le mot clé utilisé pour réaliser la requête ayant permis la récupération du tweet, ainsi que l'identifiant de l'émetteur. Notons que le contenu des tweets n'a pas été sauvegardé ici. De plus, les tweets au sein de ce jeu de données datent de fin juillet 2020 au plus tard.
Nous allons donc coupler ce jeu de données avec des tweets récents que nous allons récupérer nous même. Cependant, l'implémentation actuelle de l'API Tweepy (qui permet de récupérer des tweets sous Python) s'accompagne de nombreuses restrictions, notamment la mise à disposition des tweets datant moins de 7 jours uniquement. Ceci nous oblige donc à considérer une évolution "ponctuelle" dans le temps ("avant août 2020" VS "début février 2021") plutôt qu'une évolution continue.
Extraction des données¶
Avant de procéder à l'analyse sentimentale, il est fondamental de disposer du contenu textuel des tweets. Bien que les "vieux tweets" soient déjà labellisés, il est indispensable d’entraîner un modèle de classification sur ce jeu de données et de l'utiliser pour prédire la classe des "nouveaux tweets", afin que leur comparaison soit la plus cohérente possible.
Ainsi, dans un premier temps, nous allons récupérer le contenu textuel des vieux tweets. Pour cela, nous nous focalisons sur les tweets ayant été récoltés avec le mot clé "covid", et nous en prenons un sous-échantillon de 40 000 lignes environ. Nous utilisons ensuite les identifiants de ces tweets pour récupérer, à l'aide de l'API Tweepy : leur contenu textuel, le nombre de personnes qui suivent le compte émetteur, ainsi que la date de création du tweet.
Dans un deuxième temps, nous récupérons 10 000 tweets émis entre le 01/02/21 et le 07/02/21 en utilisant le même mot clé "covid", encore une fois pour que la comparaison soit pertinente. Nous récupérons les mêmes informations pour ces tweets (à savoir leur contenu textuel, le nombre de personnes qui suivent le compte émetteur, ainsi que la date de création du tweet). Contrairement aux requêtes précédentes où chaque tweet était récupéré avec son propre identifiant unique (donc tout identifiant ne renvoyait qu'à un seul tweet), cette requête nous renvoie tous les tweets contenant le mot clé sur plusieurs pages de résultats. Il a donc fallu parcourir ces pages avec un objet de type "Cursor" afin de ne pas lire plusieurs fois les mêmes tweets, et mettre en place un temps d'attente lorsque l'on dépassait le débit autorisé (450 tweets par 15 minutes). Cette extraction a donc duré une nuit.
Classification¶
On s'intéresse à présent à la labellisation des nouveaux tweets. Pour ce faire, nous avons testé plusieurs méthodes (dont des classifieurs SVM ou des forêts aléatoires sur la matrice TF-IDF issue des tweets), et nous avons retenu un modèle XLNET [6] (la version la plus récente de BERT) qui donnait amplement les meilleurs résultats. Nous avons réussi à solliciter notre GPU lors de l'entraînement du modèle, ce qui a considérablement réduit les temps d'exécution : de 12 heures (sans GPU) à 45 minutes (avec GPU) par epoch.
Nous utilisons donc ce modèle pour identifier les sentiments dans les nouveaux tweets selon les mêmes catégories que les anciens tweets, à savoir : colère, peur, tristesse, pas d'émotion spécifique, et joie.
A l'issue de cette étape, tous nos tweets sont labellisés, et nous pouvons maintenant nous focaliser sur la comparaison temporelle des émotions dégagées par l'opinion publique.
Voici les premières lignes de ce jeu de données :
Comparaisons¶
Dans cette partie, nous nous intéresserons à l'évolution de la répartition des sentiments dégagés des tweets ainsi que le détail du réseau sémantique en question.
Diagrammes circulaires¶
Dans cette sous-partie, nous allons comparer à l'aide de diagrammes circulaires les proportions des sentiments pour nos 2 périodes : de février à août 2020 et en février 2021. Ensuite, nous présenterons les mêmes diagrammes mais en pondérant chaque tweet associé à un sentiment par le nombre de followers de l'utilisateur.
Le diagramme circulaire de la 1ère période nous indique que les proportions de tweets pour les sentiments d'angoisse, de colère et de joie sont très proches (autour de 25%). Les émotions semblaient alors être globalement mitigées.
En revanche, le diagramme de février 2021 a des proportions assez différentes. En effet, le sentiment d'angoisse est maintenant le plus présent (une augmentation de plus de 10% de tweets), les sentiments de colère et de joie ont tous les deux des proportions qui ont baissé.
Alors est-ce assez pour supposer que ces répartitions sont significativement différentes ?
Un test d’indépendance du Chi 2 nous dit que ça ne l'est pas, mais il est quand même intéressant de noter ce changement.
Malgré l'observation d'une augmentation du sentiment d'angoisse, cela ne se reflète pas sur le test statistique puisque nous rejettons l'hypothèse d'indépendance des distributions.
Cependant, il n'est peut-être pas représentatif de se restreindre au nombre de tweets uniquement, car le niveau d'exposition des tweets et donc d'influence n'est pas homogène. En réalité, plus un tweet est exposé à des utilisateurs, plus ce tweet sera visible et donc influent.
Par exemple, il serait naïf de supposer qu'un compte ayant 10 abonnés qui dégage un sentiment de joie a le même impact qu'un compte ayant 10 millions d'abonnés et qui dégage un sentiment de peur. La réalité est qu'il y aurait une exposition beaucoup plus grande à la peur. Puisque nous avons conservé le nombre d'abonnés de chaque tweet, nous pouvons donc pondérer le nombre d'apparition des sentiments par le nombre de personnes auquel il s'expose.
Voici les diagrammes circulaires obtenus pour nos 2 périodes.
Il est intéressant de remarquer que malgré l’augmentation en nombre de publications dégageant la peur que nous avons vu sur les diagrammes précédents, l’exposition à la peur est restée identique et à 40% (ce qui est important). Nous observons également que la colère, l'angoisse et la tristesse conservent les mêmes proportions, tandis que celle de la joie a baissé de plus de 10%. Ces variations sont plus nettes en décochant la modalité "fear".
Enfin, la proportion de publications sans émotion spécifique a presque doublé entre la première et la deuxième période.
Un test d'indépendance du Chi 2 nous indique à nouveau que ce changement n'est pas lié à un changement de distribution.
Nuages de mots¶
Nous nous sommes ensuite intéressés à la comparaison des nuages de mots des tweets, par sentiment et par période (de février à juillet 2020 et en février 2021). Le nuage de mots permet de montrer visuellement la prépondérance de certains mots dans des textes, et donc des tweets dans notre étude.
Pour cela, réaliser un nettoyage du contenu des tweets est une étape importante. Nous avons alors implémenté une fonction qui supprime la ponctuation, les caractères non alphabétiques, les mots vides, et qui ne conserve que les mots dont la lemmatisation est de taille supérieure à 2. Plus un mot est de grande taille sur le nuage de mots, plus il est fréquent dans les tweets, et dans notre cas, plus il serait représentatif des discours caractérisant chacune de nos émotions.
Fear¶
Observons d'abord les nuages de mots du sentiment "angoisse" des tweets publiés avant août 2020 et en février 2021.


Les mots qui apparaissent le plus sur la première période sont "death", "case", "people", "health", "new" ou encore "pandemic". Ces mots reflètent le vocabulaire qui était notamment au centre des discussions lors du premier confinement, puisque nous étions plutôt dans l'inconnu. Les préoccupations étaient alors assez "primaires".
Le nuage de mots de ce sentiment sur la deuxième période est bien différent. Nous remarquons qu'en quelques mois les mots les plus fréquents ne sont plus du tout les mêmes. En effet, "vaccine", "social", "fear" et "isolated" n'apparaissaient pas sur le nuage de mots de la première période. Le mot le plus récurrent dans les tweets est "angoisse", ce qui montre bien le changement entre les deux périodes. Des études [4] ont montré que le manque d'interactions sociales durant le 2ème confinement et le couvre-feu ont des conséquences psychologiques réelles. Ceci pourrait expliquer que "angoisse" soit au centre des tweets de février comme le montre les diagrammes circulaires.
Sadness¶


Nous remarquons que nous retrouvons les mêmes mots entre les nuages des deux périodes. Pour ce sentiment, le vocabulaire utilisé dans les tweets ne semble pas avoir changé. Il semblerait que la tristesse mette en évidence le thème de la perte de proches [3].
Anger¶


Les nuages de mots pour le sentiment de colère semblent plus désordonnés. En effet, nous observons moins de mots très fréquents. Le nuage de mot de la première période met en avant "people", "Trump", "think", "mask" mais aussi "lockdown". Les tweets exprimeraient une colère envers les mesures prises ou pas prises par le gouvernement.
Le second met en avant "vaccine", "friend" ou "still". La colère des tweets en février serait donc liée aux vaccins, au manque d'intéractions sociales et à la frustration face à la redondance des mesures (confinement et couvre-feu), ce qui semble différent des tweets de la première période.
Joy¶


Le nuage du sentiment de joie met en avant les mots "new", "case", "positive" ou encore "thank" tandis que le deuxième ressort principalement "vaccine". Ce sentiment exprimerait donc de la gratitude et une bonne santé [3].
"Super Bowl" apparaît également puisque nous avons collecté les tweets début février, soit la veille du match dans un contexte de crise sanitaire.
Clustering¶
Concepts théoriques¶
Nous nous sommes ensuite intéressés à la possibilité de regrouper nos tweets selon les sujets de discussion qu'ils abordent. Pour cela, nous avons fait recours au modèle LDA pour "Latent Dirichlet Allocation" [5]. Il s'agit d'un modèle probabiliste génératif de corpus qui s'inscrit dans la famille du "topic modeling" (modélisation de sujet), qui est une méthode non supervisée (puisqu'on ne connait pas les sujets a priori).
Concrètement, ce modèle est fondé sur l'hypothèse qu'un document (un tweet dans notre cas) est un mélange d'un certain nombre de sujets, et que chaque sujet est caractérisé par une distribution des mots qui le composent. Le rôle du modèle est donc d'identifier ces sujets, et de représenter chaque document (chaque tweet) comme une combinaison de ces sujets. Autrement dit, le modèle suppose que chaque sujet a été généré de la manière suivante : d'abord, on tire un sujet parmi les sujets possibles selon une loi de Dirichlet, et ensuite, on choisit un mot du sujet selon la distribution multinomiale des mots au sein de ce sujet.
Ceci est résumé par la figure suivante (source) :
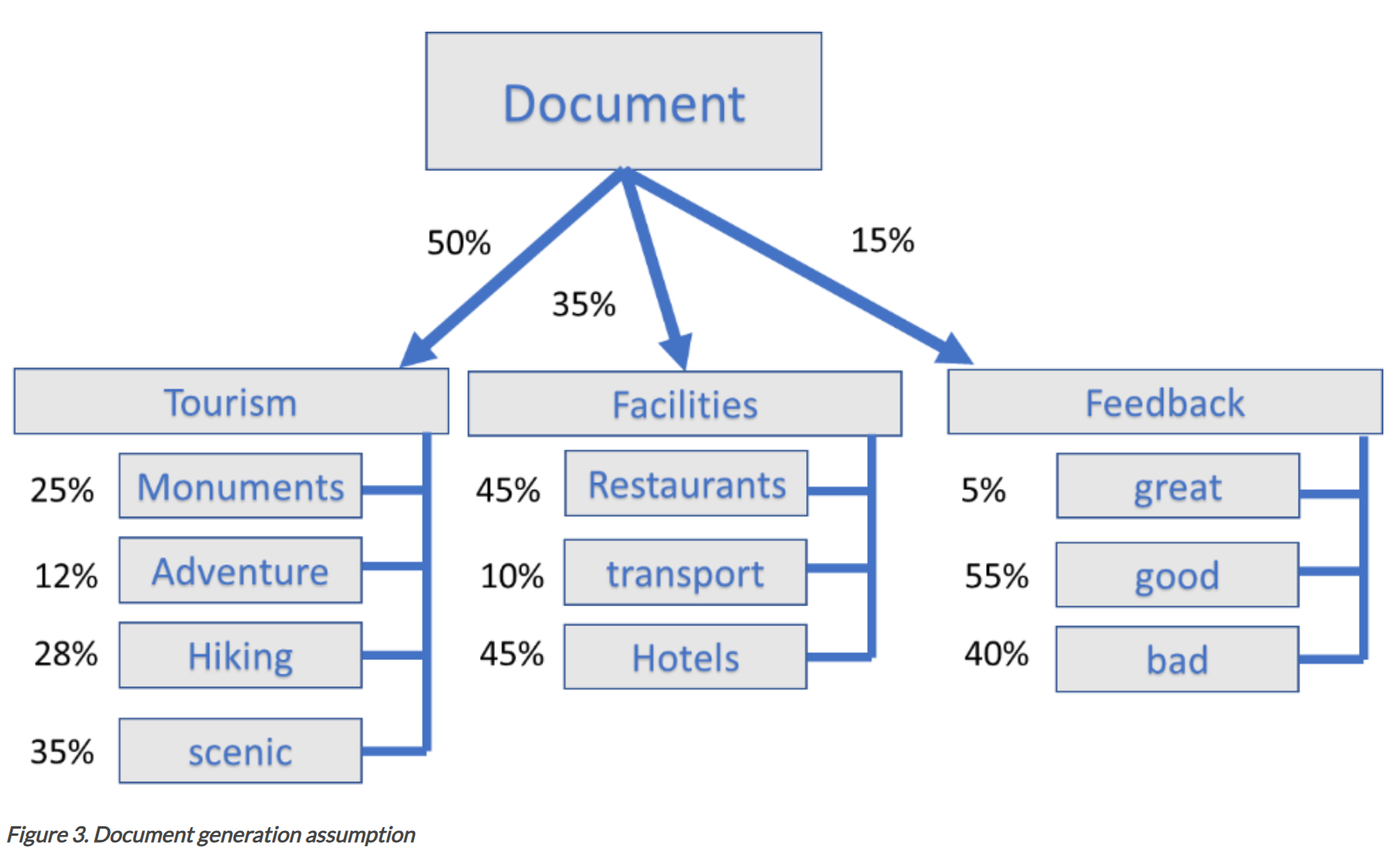
Donc pour associer les documents à des sujets, le modèle va procéder dans l'ordre inverse, et va d'abord apprendre à associer les sujets aux mots de manière itérative.
Notons que le nombre de sujets est un hyperparamètre du modèle que l'on fixe a priori. Il est usuel de le déterminer selon la connaissance du domaine ou l'interprétabilité des sujets, mais il est possible de le déterminer selon une métrique, tel que la vraisemblance du modèle.
Implémentation¶
Dans notre cas, nous avons parcouru une grille de paramètres pour trouver le meilleur modèle au sens de la maximisation de la vraisemblance. Le nombre de sujets suggéré est de 2, mais nous en prenons 3 pour pouvoir enrichir notre analyse.
Nous nettoyons d'abord nos tweets (de la même manière que précédemment), puis nous comptons le nombre d'apparitions de tous les mots (en supprimant les mots qui apparaissent dans plus de 80% des tweets ou dans moins de 2 tweets), que nous donnons en paramètre au modèle pour la phase d'entraînement.
Nous pouvons maintenant nous intéresser aux mots qui caractérisent le mieux chacun de nos 3 sujets :
Une interprétation possible serait d'attribuer la classe 0 aux nouvelles tournant autour du covid, tandis que la classe 1 serait relative aux difficultés et/ou aux ressentis des gens par rapport au covid, alors que la classe 2 porterait sur tout ce qui concerne les mesures gouvernementales.
Il est souvent utile de visualiser nos clusters de sujets pour mieux les interpréter. Pour cela ,nous proposons un outil de visualisation interactif que nous allons d'abord décrire.
A gauche, nous avons une première fenêtre qui représente les sujets (clusters) comme des cercles dont le centre est la projection en 2 dimensions des distances entre les sujets. Autrement dit, plus les cercles sont éloignés les uns des autres, plus les sujets sont distincts, et inversement, lorsque les cercles se chevauchent, cela veut dire que les sujets peuvent être confondus, ce qui laisse penser qu'il faudrait diminuer le nombre de sujets a priori.
A droite, nous avons la distribution des mots dans tout le corpus (tous les tweets) en bleu. En sélectionnant un sujet (en cliquant sur un cercle), on peut superposer la distribution des mots du sujet sélectionné sur la distribution des mots dans le corpus.
L'outil de visualisation interactif est disponible ici (ou ici).
Il est aussi possible d'interagir avec le paramètre lambda de la formule 2 de la légende (qui prend ses valeurs entre 0 et 1),. Celui-ci va influer la manière dont un mot contribue à la construction d'un sujet. Il a été démontré que le paramètre lambda a une valeur optimale de 0.6 [2].
De plus, on peut sélectionner un mot pour voir les sujets auxquels il contribue (les cercles qui ne disparaissent pas) ainsi que l'intensité de cette contribution (taille du cercle qui varie). Les résultats sont mis à jour dynamiquement.
Évolution de la popularité des sujets¶
Après avoir conservé le sujet auquel chaque tweet appartient, nous avons voulu étudier, sur la population des anciens tweets (puisqu'il s'agit des tweets qui s'inscrivant sur une assez longue durée), l'évolution de la popularité des sujets. Pour cela, nous regardons le nombre de tweets émis quotidiennement s'inscrivant dans un sujet, et ce pour tous les sujets. Nous ramenons ensuite les résultats en pourcentage (donc la somme de toutes les barres, toutes couleurs confondues, nous donne 100%).
En décochant dans un premier temps la classe 1, on peut clairement voir que les sujets 0 et 2 ont la même tendance (tendance croissante jusqu'à avril 2020, puis décroissante jusqu'à mi-juin 2020, puis stagnante). Or en affichant que la classe 2 (ou 0) et la classe 1, on voit que les tendances sont semblables jusqu'à mi-juin 2020, mais contrairement aux deux autres classes, le sujet 1 surgit en popularité dès cet instant.
Pour rappel, il s'agirait du sujet portant a priori sur les ressentis et les difficultés des utilisateurs par rapport au covid.
Regardons maintenant la répartition des nouveaux tweets au sein de ces clusters.
En classant les tweets de début février 2021 dans ces clusters, on constate que la classe 1, qui était la moins populaire avec 29% des tweets, est devenue le sujet le plus répandu, et compte 40% des tweets. Cela montre que la transition observée à l'aide de l'histogramme s'accentue toujours.
Notons que ces résultats, que ce soit l'évolution de la prépondérance des sujets jusqu'à fin juillet 2020 ou encore la tendance actuelle des tweets, sont tout à fait cohérents avec les résultats présentés dans la partie précédente.
Lien avec d'autres disciplines¶
L'identification et l'explication des raisons menant à cette transition serait un sujet d'étude aussi complexe qu'intéressant, et cela ne fait qu'appuyer la volonté de faire appel à plusieurs disciplines pour traiter cette question exprimée dans l'article [1].
Une première explication pourrait s'appuyer sur la pyramide de Maslow (source et origine de la figure) :
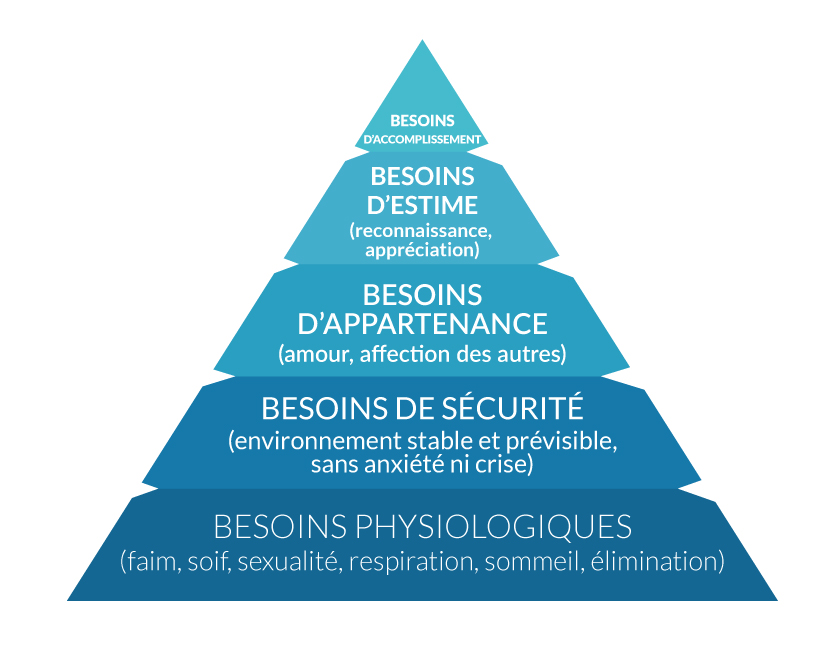
Selon Maslow, les Hommes hiérarchisent leurs besoins, et cherchent à les satisfaire dans l'ordre, en partant du bas. Autrement dit, une personne qui n'a pas satisfait les besoins d'un pilier ne s'intéresse pas aux besoins d'un pilier supérieur. On pourrait s'imaginer qu'avec le temps, les utilisateurs aient banalisé le danger de vie que pose le covid (puisqu'ils ont survécu jusque là), donc que l'instinct de "survie" du pilier du bas (besoins physiologiques) soit satisfait.
Ils commenceraient donc à être préoccupés par les besoins de sécurité et de stabilité du pilier supérieur (santé mentale, situation financière...). Ceci pourrait être une explication possible de la mutation des champs lexicaux mis en oeuvre pour l'expression des mêmes sentiments, ainsi que la nouvelle tendance thématique.
Conclusion¶
Récapitulatif de notre étude¶
Pour conclure ce travail, rappelons d'abord notre objectif : il s'agissait de mettre en oeuvre une analyse sentimentale des tweets pour étudier l'évolution du sentiment public par rapport à la crise sanitaire du COVID-19.
Pour cela, nous avons d'abord récupéré un jeu de données issu d'un article de recherche analysant des tweets datant de février 2020 jusqu'à fin juillet 2020. Nous avons couplé ce jeu de données avec des tweets datant de la première semaine de février 2021 que nous avons récupérés dynamiquement à l'aide de l'API Tweepy. Les tweets du premier jeu de données étant labellisés par le sentiment qu'ils dégagent, nous avons évalué plusieurs modèles prédictifs afin de classer similairement les nouveaux tweets pour que leur comparaison soit pertinente. Nous avons retenu le modèle XLNET qui donnait les meilleurs résultats, dont nous avons réduit le temps d'éxecution de 16 fois grâce à l'exploitation d'un GPU.
Cela nous a donc permis de commencer l'analyse sentimentale de nos tweets.
Une première analyse de la répartition des émotions montre qu'il y a plus de publications dégageant un sentiment de peur, bien que l'exposition à ce sentiment soit invariante dans le temps. On observe également un déclin de la joie au profit d'une neutralité dans les tweets. Une étude détaillée de chaque émotion montre que malgré une certaine stabilité de la répartition des sentiments, les idées qu'expriment ces sentiments sont nettement différentes. Autrement dit, les utilisateurs ne sont pas plus ou moins coléreux par exemple, mais par contre, la source de leurs colères a changé.
Suite à cela, nous avons fait appel à un modèle LDA pour organiser nos tweets selon les sujets de discussion qu'ils abordent, et nous avons intégré un outil de visualisation pour pouvoir explorer et mieux interpréter ces classes. Cela nous a permis de nous intéresser à l'évolution de la prépondérance des sujets au fil du temps, qui a mis en évidence un surgissement de tweets s'inscrivant dans la communication des ressentis et des difficultés des utilisateurs face au COVID-19.
Ce phénomène a débuté dès juillet 2020, et aujourd'hui, il s'agit du sujet le plus abordé, alors qu'il était le moins abordé il y a moins d'un an.
Il serait donc intéressant de faire appel à des disciplines annexes pour expliquer les facteurs de ce changement. La pyramide de Maslow est un exemple de sociologie qui malgré sa simplicité, pourrait expliquer de manière cohérente la mutation linguistique mise en évidence.
Commentaires sur le projet¶
Nous terminons par une appréciation brève de ce projet. La liberté accordée au choix du sujet d'étude a fait que l'élaboration de la problématique était prioritaire, et les procédés par lesquels nous allions la traiter étaient une préoccupation secondaire. Puisque nous n'avions pas traité une problématique semblable à celle-ci jusque-là, il nous a fallu prendre en main de nombreux nouveaux outils (Tweepy, clustering de sujets par LDA...). Cela a donc engendré un temps d'adaptation conséquent.
La phase de récolte de données a été particulièrement longue, puisqu'il fallait d'abord créer un compte développeur Twitter et d'en détailler notre usage, attendre la validation du projet pour pouvoir utiliser l'API, et faire face aux nombreuses restrictions (crash en cas de lecture d'un tweet privé, limites sur le nombre et le débit des tweets récoltés, solutions incompatibles avec la version actuelle de l'API sur les forums...). De plus, il a aussi fallu investir du temps pour se documenter afin d'appuyer nos interprétations par des sources légitimes.
Néanmoins, la réalisation du projet a été stimulante grâce à la liberté accordée au choix du sujet, et nous a été enrichissante (formation à Tweepy, compréhension du mode de fonctionnement de LDA, formation à des outils de visualisations interactives, etc...).
Bibliographie et sources¶
[1] Gupta R., Vishwanath A. and Yang Y., COVID-19 Twitter Dataset with Latent Topics, Sentiments and Emotions Attributes, 2020
[2] Carson Sievert and Kenneth E. Shirley, LDAvis: A method for visualizing and interpreting topics, 2014
[3] Lwin M, Lu J, Sheldenkar A, Schulz P, Shin W, Gupta R, Yang Y, Global Sentiments Surrounding the COVID-19 Pandemic on Twitter: Analysis of Twitter Trends, JMIR Public Health Surveill, 2020
[4] Aslam, F., Awan, T.M., Syed, J.H. et al., Sentiments and emotions evoked by news headlines of coronavirus disease (COVID-19) outbreak. Humanit Soc Sci Commun 7, 2020. https://doi.org/10.1057/s41599-020-0523-3
[5] David M. Blei, Andrew Y. Ng, Michael I. Jordan, Latent Dirichlet Allocation, Journal of Machine Learning Research 3, 2003.
[6] Zhilin Yang, Zihang Dai, Yiming Yang, Jaime Carbonell, Ruslan Salakhutdinov, and Quoc V. Le, Xlnet: Generalized autoregressive pretraining for language understanding, 2020.
Statistiques sur Twitter : https://www.blogdumoderateur.com/chiffres-twitter
Documentation de Tweepy (utilisé pour récupérer des tweets) : https://docs.tweepy.org/en/latest/
Documentation de SimpleTransformers (utilisé pour la classification de sentiments à l'aide de XLNET) : https://simpletransformers.ai/
Documentation de plotly (utilisé pour les diagrammes et histogrammes interactifs) : https://plotly.com/python-api-reference/
Vulgarisation du modèle LDA : https://medium.com/analytics-vidhya/the-intuition-behind-latent-dirichlet-allocation-lda-fb1e1fb01543
Documentation de l'outil de visualisation LDA (pyLDAvis, utilisé pour le clustering des tweets) : https://pyldavis.readthedocs.io/en/latest/
Guide d'interpretation de pyLDAvis : https://www.objectorientedsubject.net/2018/08/experiments-on-topic-modeling-pyldavis/#:~:text=and%20its%20lift.-,Relevance,ranked%20only%20by%20their%20lift