PAGE EN TRAVAUX
Research interests
Mes recherches se déclinent autour de 2 grand axes : la mesure de la régularité des signaux et les algorithmes évolutionnaires. Dans ces deux axes, je m’attache aux développements théoriques et à l’implementation. Enfin, je m’intéresse à la combinaison de ces outils pour créer d’autres outils et pour la résolution de problématiques réelles (biomédicales, musicales ou autres).Mathematics applied to signal enhancement, wavelets, fractals, fractal analysis, Hölderian regularity, Hölder exponents, estimation, regression, denoising, optimal rate of convergence, minimax, risk, interpolation, extrapolation, road/tyre friction, indenters, multi-scale, evolutionary algorithms, genetic programming, bloat control, stereovision, classification, matching, biomedical applications, EEG analysis, cochlear implants, virtual analogue modeling, amplifier, neural networks.
Cartography 2019
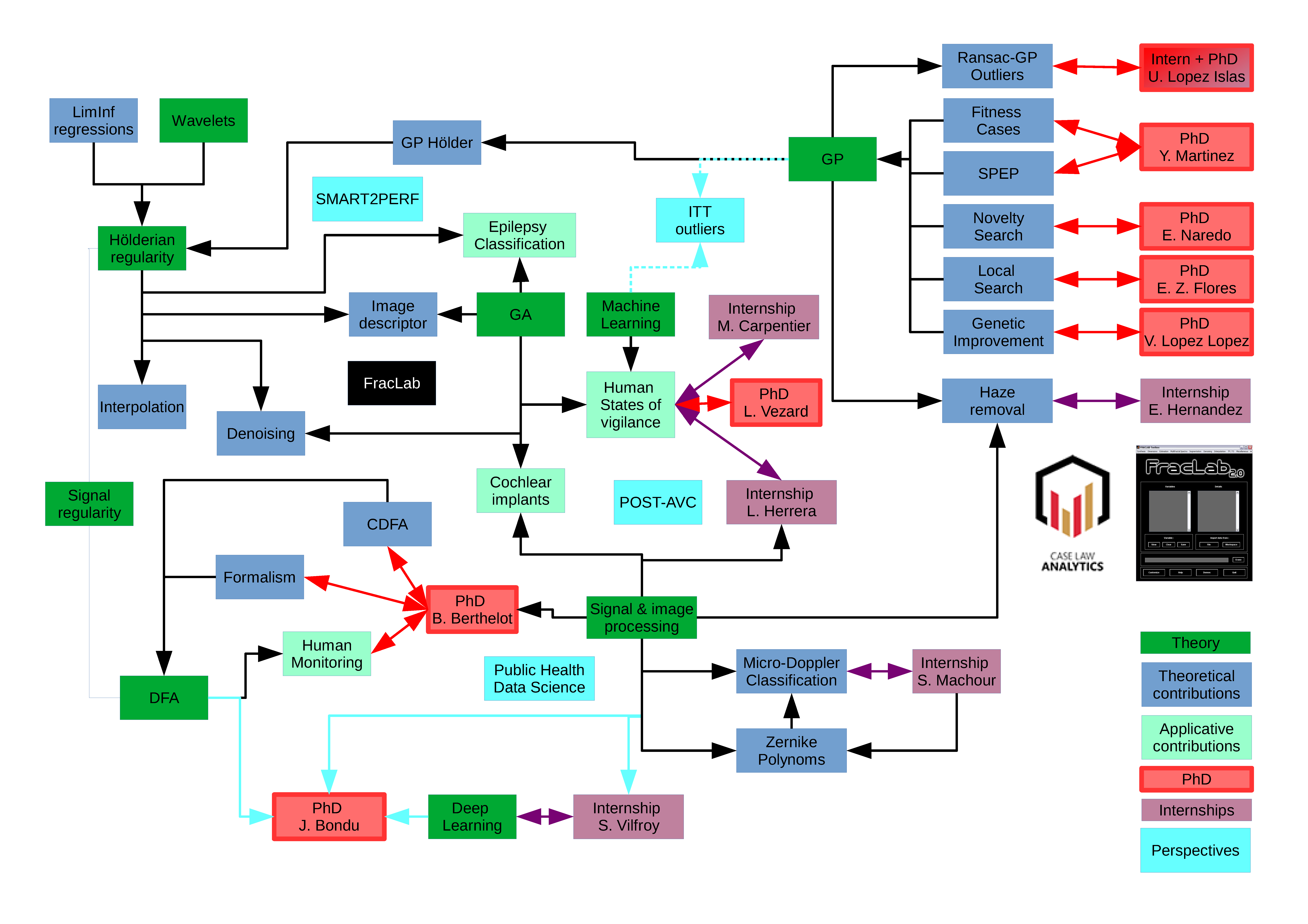
Activité scientifique
Présentation synthétique des thématiques de recherche
Mes recherches se déclinent autour de 2 grand axes : la mesure de la régularité des signaux et les algorithmes évolutionnaires. Dans ces deux axes, je m'attache aux développements théoriques et à l'implementation. Enfin, je m'intéresse à la combinaison de ces outils pour créer d'autres outils et pour la résolution de problématiques réelles (biomédicales, musicales, human monitoring ou autres).
Estimation de la régularité et contributions théoriques
Régularité Hölderienne :
De nombreuses applications montrent que la caractérisation de la régularité locale des signaux obtenue via des techniques à base d'ondelettes ou d'outils
d'analyse fractale est pertinente pour leur description et leur traitement [Legrand2009].
Bien que l'analyse de la régularité d'un signal et son estimation constituent une problématique assez récente dans le domaine du traitement du signal,
il s'agit d'une des caractéristique fondamentale d'un signal même s'il existe une infinité de signaux présentant
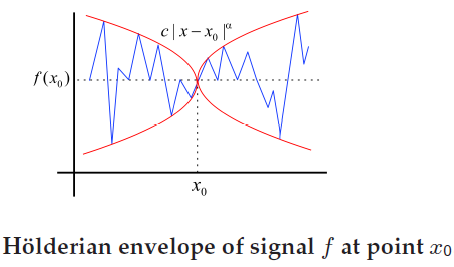
la même régularité en chaque point. Une branche de l'analyse fractale, l'analyse de la régularité Hölderienne,
offre des outils mathématiques permettant de caractériser la régularité d'un signal [Legrand2009].
En particulier, l'exposant de Hölder ponctuel est particulièrement adapté à la mesure de la régularité des signaux.
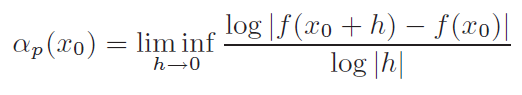
Estimation de l'exposant de Hölder :
Plusieurs méthodes sont envisageables pour estimer l'exposant de Hölder. La plus naturelle, car elle suit la définition de l'exposant, consiste à étudier les oscillations autour du point considéré (Tricot1995).
Une seconde méthode d’estimation de la régularité Holderienne découle d’un théorème de Stéphane Jaffard et se base sur une décomposition en ondelettes [Jaffard2004].Contributions :
- A partir de ces méthode d'estimation de l'exposant de Hölder, il a été possible de construire des méthodes de débruitage présentant des taux de convergence asymptotiques similaires aux méthodes les plus performantes de la littérature [Legrand2004], [Legrand2003], [LVLEGRAND2003].
- Il a été aussi possible de développer une méthode d'interpolation conservant la régularité Höldérienne quelque soit le nombre d'interpolations choisi [LegrandInterp2003], [LVLegrandInterp2006].
- Ces contributions ont été intégrées à la toolbox Fraclab [SigProcFracLab].
Coefficient de Hurst et DFA :
Dans le cadre de la thèse CIFRE Thales de Bastien Berthelot, je me suis intéressé à la méthode de Detrended Fluctuation Analysis (DFA) et ses variantes pour l'estimation du coefficient de Hurst. Ce coefficient, classiquement noté H [1], permet d'évaluer la dépendance à long terme (long range dependance, LRD). Ce concept peut se rattacher à la mémoire d'un processus.
Le lecteur peut se référer à [2] pour une étude approfondie de la LRD. Estimer H peut s'avérer pertinent pour la classification de signaux de différents types, notamment physiologiques. Ce marqueur a en effet été utilisé pour caractériser des signaux électroencéphalogrammes (EEG) [3] et électrocardiogrammes [4], des mouvements oculaires [5] ou encore des signaux de parole [6]. Ce coefficient, dans le cadre de la thèse de Bastien Berthelot a été utilisé comme signature à extraire de biosignaux pour des application de type crew monitoring. Plusieurs contributions théoriques ont été proposées au cours de cette thèse, accompagnées par le dépôt de deux brevets (un français et un français puis étendu sur l'europe, la chine et les états-unis) et un troisième en cours de dépôt. De plus des contributions sur des plans applicatifs ont été réalisées.
Au vu du grand intérêt qu'il suscite chez les praticiens, et de sa pertinence établie pour la caractérisation d'états physiologiques délétères, le coefficient de Hurst H, et en particulier son estimation font l'objet de nombreux travaux. Parmi les différents estimateurs du coefficient de Hurst proposés ces dernières années, le DFA apparaît comme une méthode simple à mettre en œuvre, offrant de bonnes performances en termes de précision d'estimation, tout en étant peu coûteuse en temps d'exécution. Il repose sur l'étude de la variance des fluctuations, également appelée fonction de fluctuation ou résidu, autour de la tendance du signal centré et intégré. La tendance est modélisée comme une concaténation de segments de droite. Il existe différentes variantes de cette méthode, telles que le DFA d'ordre supérieur [Kiyono2015], l'AFA, pour adaptive fractal analysis [Riley2012] ou le DMA, pour detrending moving average [DMA_Alessio]. Elles différent par leur manière d'estimer la tendance (voir figure 1 pour certaines méthodes de la littérature et certaines de nos contributions), et peuvent se décomposer en deux catégories : d'une part, les estimateurs fondés sur une modélisation a priori de la tendance, comme le DFA et l'AFA, et d'autre part ceux où la tendance résulte d'un filtrage linéaire invariant du signal intégré, comme le DMA.
Algorithmes évolutionnaires et contributions théoriques
Algorithmes génétiques et stratégies d'évolution :
Les algorithmes génétiques et les stratégies d'évolution sont des algorithmes d'optimisation basés sur la théorie darwinienne de l'évolution (De Jong (1975) [1] et Holland (1975) [2]). L'idée générale est qu'une population de solutions potentielles va améliorer ses caractéristiques au fil du temps par le biais de mutations génétiques et de croisements afin de s'adapter au mieux à son environnement. Le but de ces algorithmes est d'optimiser une fonction d'évaluation (fitness) sur un espace de recherche. Des individus (appelés "parents" et correspondant à des points de l'espace de recherche) vont être créés afin de former une population initiale diversifiée. Ils sont représentés par des génomes (codes binaires ou réels, de taille fixe ou variable). À l'aide d'opérateurs de mutation et de croisement, les parents vont donner naissance à des enfants qui vont être évalués à leur tour. Les meilleurs individus (enfants et/ou parents inclus) vont survivre. L'algorithme peut, par exemple, être itéré jusqu'à ce que tous les individus soient identiques (convergence de l'algorithme).
[1] De Jong, K. A. (1975). An analysis of the behavior of a class of genetic adaptive systems. PhD thesis, University of Michigan.
[2] Holland, J. H. (1975). Adaptation in natural and artificial systems. University of Michigan Press, Ann Arbor.
Exemple de minimisation d'une fonction de R^2 dans R par une stratégie d'évolution
Exemple de minimisation d'un trajet (TSP) par un algorithme génétique
Programmation génétique (GP) :
La programmation génétique est assez similaire aux algorithmes génétiques. Toutefois, l'espace de recherche est alors un espace fonctionnel. En effet, dans le cadre de la programmation génétique, on ne cherche plus à trouver un jeu de paramètres optimisant un critère mais à construire une fonction.
Dans la forme classique du GP, chaque solution est représentée sous forme d'arbre qui peut représenter une fonction. Les arbres sont construits en utilisant des éléments de deux ensembles, un ensemble de fonctions et un ensemble de terminaux. Ces deux ensembles définissent l'espace de recherche du GP. Des algorithmes courant, le GP est l'une des formes les plus avancées de recherche évolutionnaire.
Contributions :
- La programmation génétique a montré des résultats impressionnants dans divers domaines d'application. Toutefois, il reste encore des limitations pratiques à dépasser, en particulier, son coût computationnel, le sur-apprentissage et l'accroissement excessif de la taille des arbres (parfois sans corrélation avec l'amélioration de la qualité de l'individu, ce qu'on appelle bloat). Il est apparu au travers de la thèse de Yuliana Martinez que le choix de la méthode de calcul du fitness a une influence sur le bloat, le temps de calcul et la qualité du résultat sur le plan du sur-apprentissage [1][2][3].
- Déterminer la difficulté d'un problème est une question importante dans le domaine de l'évolution artificielle, et ce depuis des années. D'un point de vue algorithmique, la difficulté d'un problème peut être associée au temps d'exécution ou à la mémoire nécessaire pour trouver une solution optimale, mais aussi à la qualité de la solution proposée en sortie. Dans le cadre de la thèse de Yuliana Martinez, nous nous sommes intéressés à la constructions de modèles capables de prédire les performances d'un GP-classifier (classifieur construit par programmation génétique) sans avoir besoin d'exécuter le programme ni avoir besoin d'échantillonner des solutions potentielles dans l'espace de recherche [2][4][5][6]. Le principe est le suivant : Pour un problème de classification donné, nous appliquons une étape de pré-processing afin de simplifier le processus d'extraction des caractéristiques. Puis nous effectuons l'étape d'extraction des caractéristiques du problème. Enfin, nous utilisons un modèle PEP (prediction of expected performance), qui prend en entrée les caractéristiques du problème et produit en sortie l'erreur de classification prédite sur l'ensemble de test. Pour construire le modèle PEP, nous avons utilisé une méthode d'apprentissage supervisé avec un GP. Ensuite, pour raffiner ce travail, nous avons élaboré une approche utilisant plusieurs modèles PEP, chacun devenant maintenant un SPEP (specialist predictors of expected performance) spécialisé pour un groupe particulier de problèmes. Il s'avère que les modèles PEP et SPEP ont été capables de prédire de manière précise les performances d'un GP-classifier et que l'approche SPEP a donné les meilleurs résultats.
- La programmation génétique est un outil puissant mais comme indiqué précédemment, il comporte quelques inconvénients dans sa version habituellement décrite dans la littérature. Pendant la thèse de Emigdio Z. Flores, nous nous sommes intéressés à l'amélioration de la vitesse de convergence de ces algorithmes et au contrôle du bloat en ajoutant une étape d'optimisation locale autour des individus (arbres) [1][2][3]. En effet, à travers la paramétrisation des arbres (individus) et une optimisation locale, la recherche du GP va converger plus rapidement vers des solutions de haute qualité. Dans un premier temps, nous avons simplement ajouté un paramètre, un coefficient de poids devant chaque fonction du set des fonctions (atomes disponibles pour construire l'arbre). Dans un second temps, nous avons déterminé à quels individus et à quelles générations il était pertinent d'appliquer cette optimisation locale. Les résultats ont montré que la meilleure stratégie consiste à appliquer l'optimisation locale sur tous les individus ou sur un échantillon aléatoire des meilleurs (au sens du fitness) individus à chaque génération.
- Le Novelty search ou NS est une approche unique en optimisation où une fonction objectif explicite est remplacée par une mesure de la "nouveauté" de la solution. Bien que le NS ait été utilisé en robotique évolutionnaire, son utilité pour les problèmes classiques de machine learning était jusqu'alors restée inexplorée. C'est ce manque qui a motivé la thèse de Enrique Naredo. En effet, il a été question de concevoir un GP basé sur du NS (GP-NS) pour des problèmes de machine learning communs. Les contributions issues de ces travaux sont les suivantes : Il a été montré que le NS peut résoudre des problèmes réels et synthétiques de classification, de clustering et de régression symbolique. De plus, une étude sur le bloat et la dynamique de recherche du GP-NS a été menée et deux nouvelles version performantes de NS ont été proposées et éprouvées [naredo:hal-01389049].
Combinaison des outils, développement théoriques et applications
En combinant les outils présentés ci-dessus avec du traitement du signal et du machine learning plus "conventionnel", il a été possible de produire, entre autres, les travaux suivants :
- Estimation de l'exposant de Hölder par programmation génétique. Construction de descripteurs locaux dans une image. [1] [2] [3] [4]
- Débruitage évolutionnaire, traitement d'images, suppression de brouillard. [5] [6] [7]
- Réglage automatique d'implants cochléaires. [8] [9] [10] [11] [12] [13]
- Classification de signaux EEG, d'états psychophysiologiques et de phases épileptiques. [14] [15] [16] [17] [18] [19] [20] [21]
- Radar, micro-Doppler, traitement du signal et machine learning. corretja:hal-00643369, machhour:hal-01795520.
- Traitement du signal et DFA pour mesurer la vigilance d'un pilote d'avion berthelot:hal-02174262.
